
What is proactive data quality testing?
Learn the three principles of proactive data quality for modern data engineering: shifting tests left in the workflow, implementing a data checklist before shipping, and automating data quality checks.
In this section, we’ll talk about the 3 principles of **proactive data quality **that should govern how modern data engineering teams operate.
1. A better workflow by shifting data to the left
We don’t need to reinvent the wheel here, as our colleagues in software development have already figured it out with shift-left testing.
Shift-left testing is pretty simple: You want to test as early as you can in the development cycle. In data engineering, this means that you want to QA any changes to your data during at source-level, development, and deployment, and the very last point should be in production.

You can do checks at any stage in this process, but anything done at levels 0 and 1 in the diagram above are not considered proactive data quality testing. It’s obvious why for level 0: if stakeholders are the ones who flag questionable data to the data team, trust has already been lost, and anything done is to minimize further damage, not prevent it. For level 1, we’ve previously talked about how data observability tools are meant to monitor anomalies during production–they’re an important part of your overall data quality strategy, but not necessarily proactive.
That leaves us with levels 2 and 3. It seems pretty obvious that any defense system worth its salt is only effective when put up before the threat emerges. Yet, it’s surprising how often this is overlooked in data quality management. Just how far can we shift data quality testing to the left? Let’s take a look at our options next.
Proactive development testing
This is the furthest we can shift data testing to the left, when we haven’t even committed our code changes to the repository. But should we? Yes! Proactive development testing is crucial, especially when developing your dbt models.
There are so many tools that make data quality testing possible during this stage:
- Modern IDEs and dbt now allow you to test whether SQL queries compile properly.
- Pre-commit hooks to enforce company policies across developers can be first run locally, not just in CI pipelines.
- Data diff locally to see how code in development changes the data before you commit any code.
- dbt tests are useful in dbt projects for running tests with pre-defined criteria (e.g. verifying data types, columns, referential integrity, and business logic). Before you reach for the next quick fix, first try and whiteboard the existing workflow for a development cycle to figure out where you can integrate any or all of these proactive data quality checks that make it part of the existing development process.
Proactive deployment testing
This stage is your last chance to catch and fix any issues before they hit production-grade systems, often in some time of continuous integration (CI) process. You can implement this in three steps:
- **Version control **all data-processing code: This is pretty easy as there are many modern frameworks (e.g. dbt) that support version control for data processing code.
- Data diff to know how the data changes when the code changes: Similar to how you should git diff code between PRs, you should diff your data during your CI process, so that any changes are made clear to the rest of the team and you create consistent (and mandatory) data quality checks. Both the developer and the reviewer have the information they need to decide whether any data changes were intended, and every PR undergoes the same level of testing and scrutiny.
- Data assertions to validate the most critical business assumptions about the data: It’s impractical to write assertions to cover every possible outcome, so focus on the most important ones. Tools like dbt tests and Great Expectations make it easy to implement. There’s no guaranteeing every data engineer runs the same set of tests on their data during their development periods. By leveraging data quality checks in your CI process, you’re automatically ensuring every single code change undergoes the same data quality testing standards before being merged in, creating an additional data governance practice.
2. A data checklist before shipping
In 2009, a book called The Checklist Manifesto made waves by making a very simple idea popular: That experts should use checklists to ensure they don’t overlook critical steps in complex systems they operate. The author, Atul Gawande, is a surgeon who was looking for ways to reduce “errors of ineptitude” – errors that we really should not be making given the information and tools available to us today.
Checklists have since transformed how many teams and industries operate; data engineering is no stranger to this mental model as we have long adopted the practice of Continuous Integration and Continuous Deployment. But we vary greatly in what we put on our checklist, and this largely accounts for why data teams still struggle with data quality.
Every time you make a change anywhere in the data pipeline, whether that’s a small change to a schema or a significant refactoring of spaghetti SQL ETL/ELT code, you need to check for three things:
☑️ Is your data correct?
☑️ How will it impact downstream dependencies?
☑️ How will it impact your infrastructure?
These three should be at the center of your data team’s checklist. It proactively safeguards your production environment against errors of ineptitude. Let’s take a look at each one of these.
Data correctness
Verify that any changes you made to the data pipeline produce accurate results. What this checklist looks like:
- Double-checking data integrity, such as ensuring primary key uniqueness, referential integrity, and data consistency.
- Making sure that the data impacted by modified SQL or dbt models is outputting what you expect.
- That changes to a data transformation process reflect the intended aggregation logic, without any SQL compilation errors or incorrect data values.
Downstream impact
dbt and SQL models are so deeply interlinked with each other, data sources, and BI tools, that even making minor changes in one place can blow up any downstream dependencies. What this checklist looks like:
- Examining the potential ripple effects on dependent systems, such as key analytics dashboards, machine learning models, or downstream applications.
- Ensuring that modifications do not inadvertently alter business definitions or calculations, which could lead to inaccuracies in downstream metrics or analyses.
- Anticipating any disruptions or issues that may arise as a result of the changes and taking proactive measures to mitigate them. Column-level lineage is fast becoming an industry standard feature as it offers a visualization of how your columns interrelate between different data assets, such as tables, columns, views, and reports. It’s a handy way to trace the lineage of specific columns and drill down into which specific data asset(s) might be impacted by a change further upstream.
Infrastructure impact
Changes in the data pipeline can have similar implications for the underlying infrastructure and computing resources. What this checklist looks like:
- Evaluating the performance implications of the changes, including their impact on data timeliness, service level agreements (SLAs), and overall system efficiency.
- Determining whether the changes require adjustments to computing resources, such as resizing database warehouses or clusters, to accommodate increased processing demands.
- Anticipating any potential bottlenecks or scalability issues that may arise and taking preemptive action to optimize infrastructure resources accordingly.
3. Automate, automate, automate
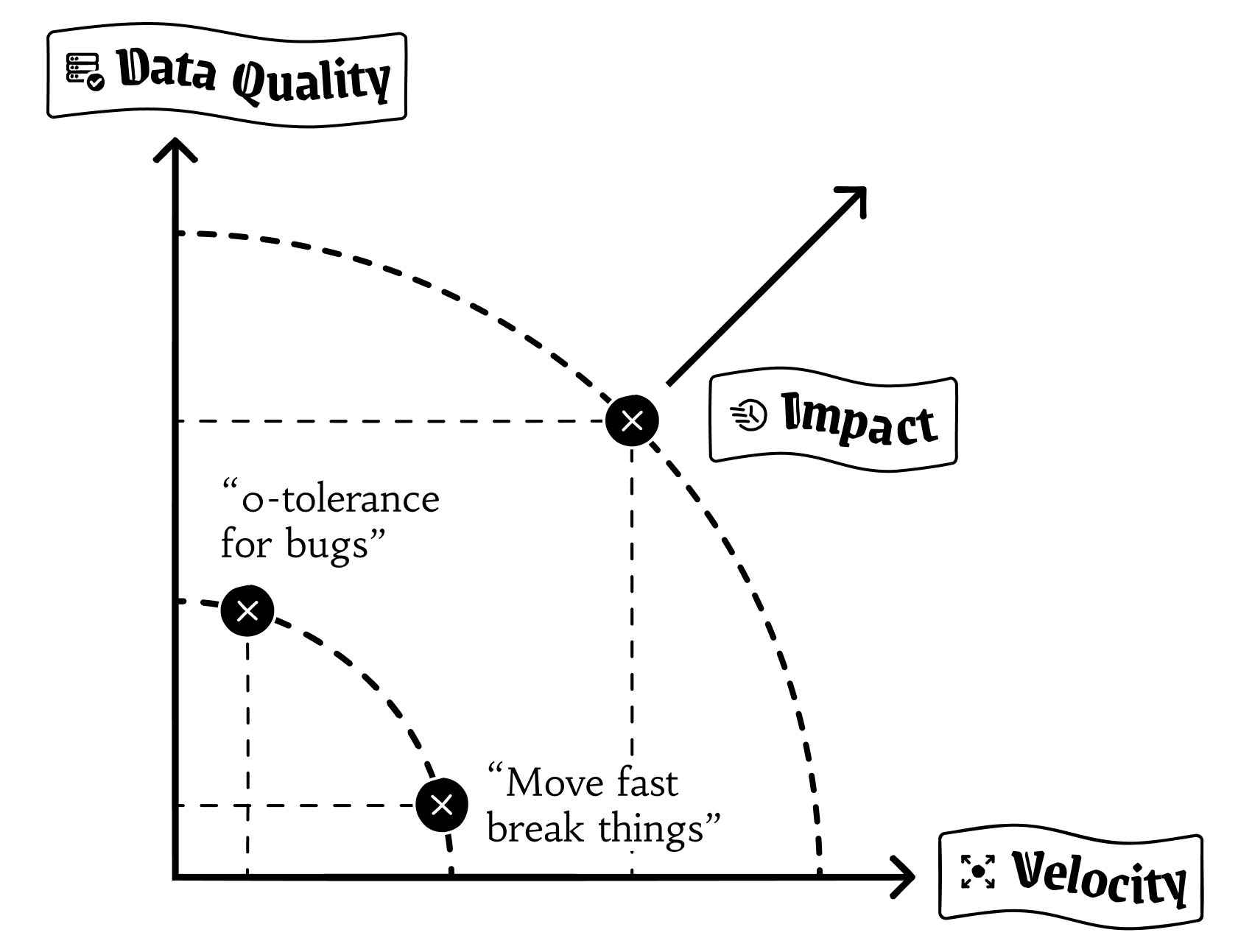
In our experience, and in conversations with other senior data engineers working at top tech companies, there seem to be two existing approaches to data quality testing.
In teams that prioritize quality over speed, you can find staff-level data engineers manually QA-ing every change to financial data pipelines for 4-5 days, and submitting “acceptance” spreadsheets before their PRs get approved.
For other teams that prioritize speed over quality, it’s unthinkable to wait an entire week to test a change. Instead, they work less formally and send a Slack update to the team announcing the change, and, “let me know if you notice anything wrong.”
 Both of these approaches have serious trade-offs. Can you really afford to ship so slowly and bet that your competition is doing the same? Could you imagine a data quality incident so severe that it results in regulatory fines or loss of customer trust?
Both of these approaches have serious trade-offs. Can you really afford to ship so slowly and bet that your competition is doing the same? Could you imagine a data quality incident so severe that it results in regulatory fines or loss of customer trust?
There’s a third way. Once you have the first two proactive data quality principles in place, workflows that make sense and checklists against errors, you know exactly what you’re shipping with each pull request. You can do away with manual QA tests with an automated data quality testing process during migrations, replication, and CI processes. No more ad hoc checks that are applied unevenly against changes and thus prone to missing data quality problems in a predictable cycle.
 Once you’ve mapped out your existing workflow, identified the gaps and opportunities for improvement, you can then figure out a process to integrate the three-tiers of quality checks– data correctness, downstream impact, and infrastructure impact–that automatically run with each PR before anything gets merged to production. These three tiers form a formidable defense against data quality lapses, not unlike a series of fortified walls and moats encircling a castle.
Once you’ve mapped out your existing workflow, identified the gaps and opportunities for improvement, you can then figure out a process to integrate the three-tiers of quality checks– data correctness, downstream impact, and infrastructure impact–that automatically run with each PR before anything gets merged to production. These three tiers form a formidable defense against data quality lapses, not unlike a series of fortified walls and moats encircling a castle.