

What is data diffing?
We're unpacking all things data diffing—what it is, how it differs from standard dbt tests, and why your team should be using it to test your data.


If you’re new to Datafold, welcome! If you’re a Datafold and data diffing connoisseur, welcome back (this will be a nice refresher 😉).
We’re unpacking what you’ve probably seen us talk about countless times: data diffing—what it is, why we support it, and how it’s relevant to you on your data testing journey. In particular, we’ll cover:
- How we define data diffing
- Why data diffing is important
- Use cases for data diffing
- What data diffing in Datafold looks like So, let’s get into it!
Defining data diffing
In the simplest of terms,** data diffing is the act of comparing two tables to check whether every value has changed, stayed the same, been added, or removed between the two tables.** To compare it to something familiar, you can think of a data diff as a git code diff, but for the tables in your data warehouse. You’ll typically perform data diffs between the same table in different databases (development and production) or across data warehouses to confirm parity between two tables.
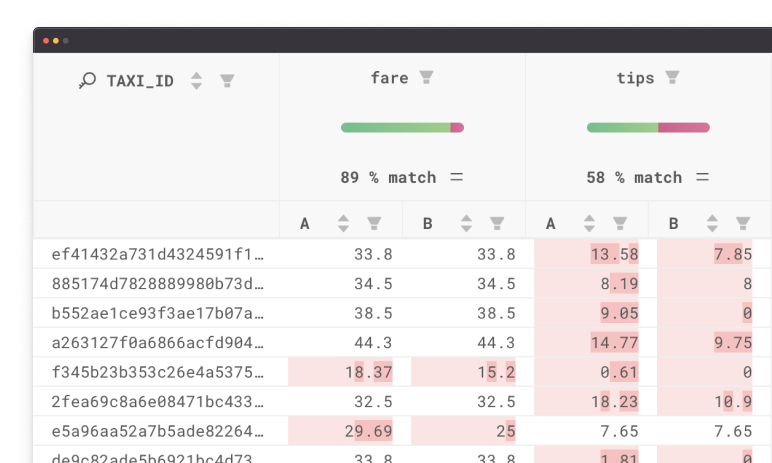 An output of a data diff from Datafold will typically take two forms: a high-level data diff overview or value-level diff.
An output of a data diff from Datafold will typically take two forms: a high-level data diff overview or value-level diff.
Data diff overview
In a data diff overview, you can receive a high-level overview of how table A (typically your development or staging environment) differs from table B (typically in your production environment). Information in a your diff overview will include:
- Schema differences (Are there more or less columns between the two tables?)
- Primary key differences (Do tables A and B have the same or different amount of primary keys?)
- Row differences (Do tables A and B have different numbers of rows? Do any rows have different column values between tables A and B?)
Datafold will automatically add a comment to your git repo for your SQL models (say in a dbt project or something similar), providing the high-level differences between your production environment and your development or staging environment. In the image below, you can see the the production environment off of the main branch has 82 more rows than the PR’s version, indicating that there’s been some type of potential data loss. You can also see the columns that have data differences, like
sub_planandsub_ price, and see how much they differ from each other.
 Diff overviews are useful for getting a fast understanding of the important structural differences between two tables and ensuring primary keys match as expected. For dbt developers, you’ll often data diff between the dev and prod versions of a dbt model, so you can clearly understand how your code changes are impacting the underlying data. For teams undergoing data migrations or replication, this high-level diff result is useful for quickly validating parity between tables in different data warehouses.
Diff overviews are useful for getting a fast understanding of the important structural differences between two tables and ensuring primary keys match as expected. For dbt developers, you’ll often data diff between the dev and prod versions of a dbt model, so you can clearly understand how your code changes are impacting the underlying data. For teams undergoing data migrations or replication, this high-level diff result is useful for quickly validating parity between tables in different data warehouses.
Value-level diff
When there are value-level diffs—meaning there’s at least one row that has a column with a differing value between two tables—you can leverage value-level differences to inspect row-level differences.
In the image below, you can see the value-level differences between the two version of a dim_orgs model—one located in Databricks and one located in Snowflake. Value-level diffs show you row-by-row how column values may have changed or differ between two tables. For example, in the scenario below, we see the timestamp column **created_at **differs considerably between the two version of the table.
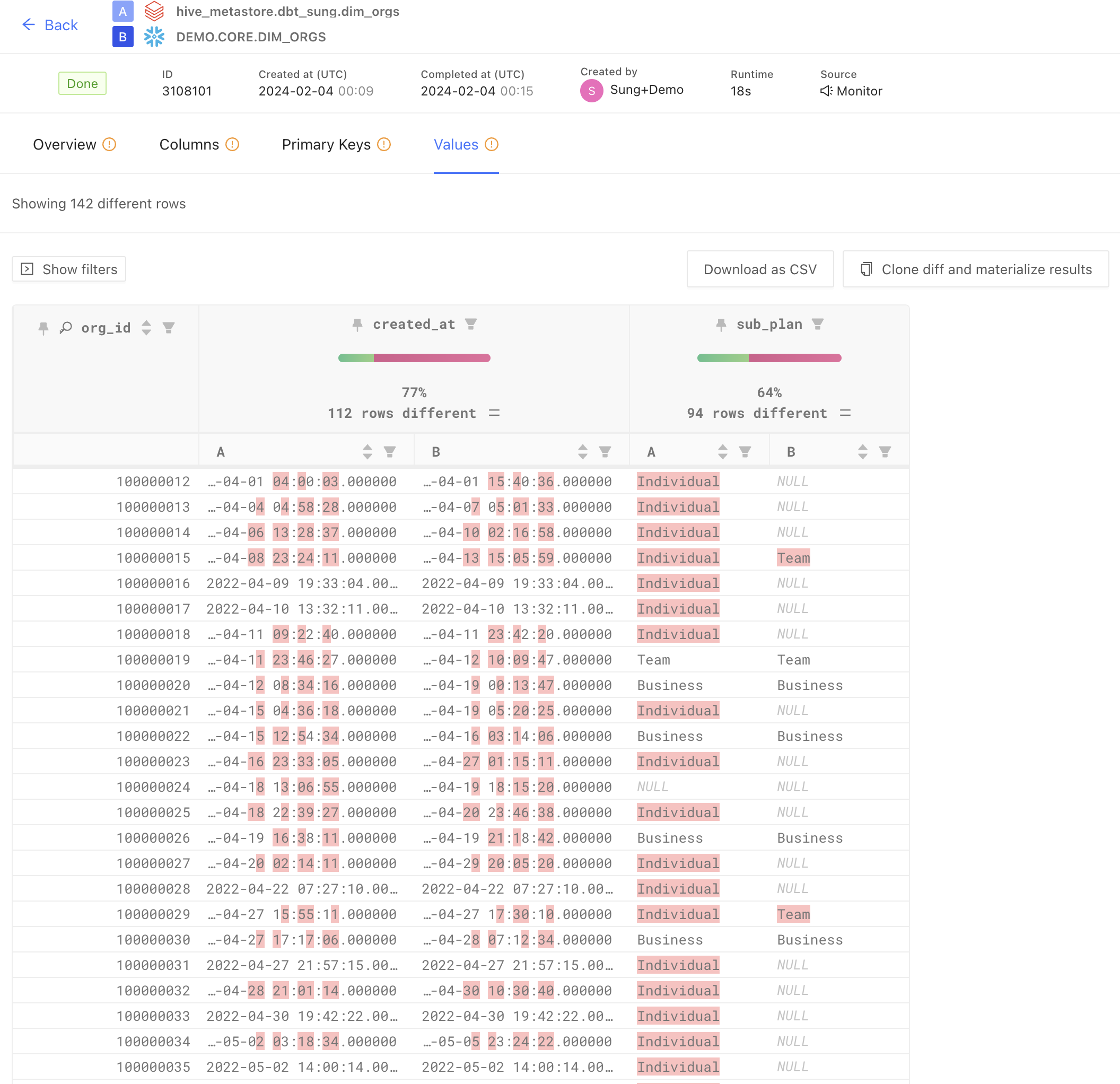 With value-level data diffs, you can inspect individual rows to understand why a value has changed and identify the code change that led to that difference. It’s important to note, differences are usually expected with code changes! Data diffing is not a way to tell you whether a code change is good or bad (you often want your data to be different or changed!)—it’s up to you and your team to determine if differences between tables are **acceptable and expected **or something that would be a data quality issue if merged into production.
With value-level data diffs, you can inspect individual rows to understand why a value has changed and identify the code change that led to that difference. It’s important to note, differences are usually expected with code changes! Data diffing is not a way to tell you whether a code change is good or bad (you often want your data to be different or changed!)—it’s up to you and your team to determine if differences between tables are **acceptable and expected **or something that would be a data quality issue if merged into production.
For teams undergoing data migrations or ongoing data replication, value-level diffs are a useful way to understand if copied data is as expected in your new data warehouse.
When we hit the dbt test ceiling, we diff
At this point, you may be wondering: why would I need this level of granularity? Does my existing testing suite not cover data diff use cases? How do I know if I should be diffing my data?
We’ve seen developers and teams adopt data diffing for many reasons:
- dbt tests and packages don’t capture unexpected changes: dbt tests, unit tests, and other test packages are great for asserting expected changes (e.g. ensuring primary keys are unique and not null, downstream tables maintain referential integrity), but often fail to catch unexpected or unforeseen changes. For example, there’s no dbt test that currently will alert you if there’s a changed first_name value or a slightly different event_timestamp.
- Manual checks don’t scale with your data and team: I have personally written more ad hoc queries to check that my prod and dev versions of a table match my expectations than I would like to admit. These queries are fine for quick gut-checks, but don’t catch every scenario and don’t scale with your data and dbt project growth.
- Countless dbt test failures create a noisy data quality landscape: When you have hundreds or thousands of dbt models with tests of their own, wading through those test results can be difficult to identify noise from value. With data diffs, you can see both high-level and row-level differences to quickly determine the important from the pandemonium. This is not an exhaustive list of why you may want to data diff, but provides an overview of why many teams are adding data diffing to their data quality testing practices.
Data diffing use cases
The primary use cases for data diffing are during dbt code development, deployment, data migrations, and data replication.
- dbt development: Data diffing on top of your foundational dbt tests allows you to develop dbt models with more speed and confidence. Know exactly how your code changes will impact the underlying data before opening up that PR.
- dbt deployment: To guarantee data quality issues don’t slip through, automate data diffs during your CI process. By adding a data diff check in CI, you and your team can see diff results and only allow approved diffs to enter your production environment.
- Data migrations: During database migrations, data diff across data warehouses to ensure legacy systems and new systems match as expected. Expedite database migrations by quickly data diffing between thousands of tables between systems versus manual comparisons between legacy and new warehouses.
- Data replication: For teams that need to replicate data across databases or data warehouses, ensure parity by running data diffs between the locations (ex: Postgres to Snowflake to ingest product usage data). Immediately be aware if there are differences in your replicated tables by diffing replicated and original tables in your two systems.
Data diffing with Datafold
For teams that want to automate and scale data diffs with their team, leverage Datafold Cloud’s robust diffing features and CI integration. Using Datafold, you can add diff results (both diff overviews and value-level diffs) as an automated comment in your PR, so you and your team can see the immediate potential impact of dbt code changes. In addition, Datafold’s diffing capabilities supports thorough impact analysis, so you can clearly identify downstream dbt models, BI tools, or data apps that are impacted by your dbt code changes. With Datafold Cloud by your side, you only allow data diffs to be merged in that you and your team approve.
Interested in getting started with diffing? Check out the following resources:
- For teams who want to see Datafold in action, see a live demo to learn more and get all your pressing questions answered Happy diffing!



