

What is CI, and why should you care about it
Data teams on dbt who don’t have CI configured are missing out massively.


If we had to create the “dbt hierarchy of needs,” it would probably look a little like this:
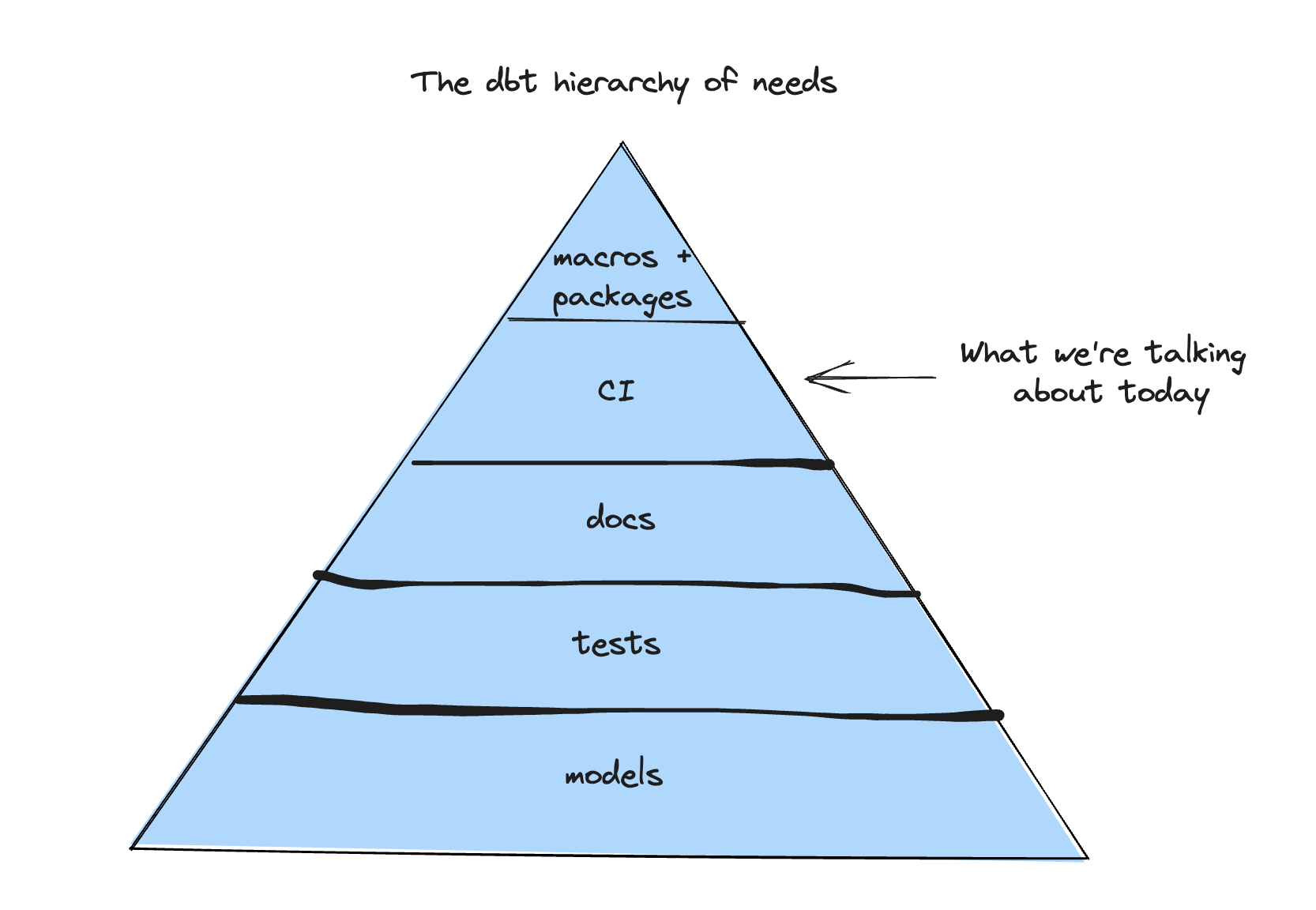 At this point, you probably have a strong understanding of dbt models, tests, documentation, materializations—the foundations of your dbt project. But does it mean to go up a level on the pyramid…what is CI, and why are we seeing modern data teams adopting this software engineering principle en masse?
At this point, you probably have a strong understanding of dbt models, tests, documentation, materializations—the foundations of your dbt project. But does it mean to go up a level on the pyramid…what is CI, and why are we seeing modern data teams adopting this software engineering principle en masse?
CI stands for Continuous Integration, which roughly translates to: “how do we get new code ready to ship to production?” For analytics engineers, it’s the process of integrating new dbt SQL code into the codebase: packaging code changes and deploying them to production with automatic tests and checks to ensure code changes meet your team’s standards.
Say your team uses version control and keeps dbt code in a GitHub/GitLab repository. (Good!)
Your deployment process probably looks something like this:
- Alice, the analytics engineer, changes some dbt model SQL code.
- Alice opens a PR/MR and asks Bob for a review.
- Bob performs code review, decides it looks good after a quick eyeball, and gives a 👍.
- Alice merges the code and kicks off a production run to apply code changes to data. Without CI, this whole process relies on Bob, who is probably unfamiliar with the code and the context, to validate the code that Alice wrote. How much can Bob tell about the quality of the work by scrolling through lines of code in a PR? Not much, I can tell you, having reviewed hundreds of PRs in my data engineering days.
Bob asks questions like:
- What is this code change doing, exactly?
- How will this new filtering logic affect the data?
- Will anything break downstream?
- Did Alice run tests?
- I can never remember…do we use trailing or leading commas?
- That new CASE WHEN logic looks weirdly suspicious…aren’t we using customer_ltv in one of the exec dashboards? Should we let our finance team know about this?
- Does this code even compile? Without CI, you run a very high risk of merging and deploying bad code, from code that doesn’t run/compile to code that breaks something downstream (like your CFO’s favorite dashboard) or unexpectedly changes metrics definitions.
Without CI, it’s virtually impossible to impose any code standards for mandatory documentation or code formatting.
Without CI, the team ends up spending unproductive hours in a back-and-forth about changes and how they should be testing, getting annoyed with nitpicking code styles, anxiously rubber stamping “LGTM 👍,” and after all that effort, spending half of tomorrow in another fire drill.
CI builds data in a separate environment before shipping the code
The concept of a separated data environment is central to implementing CI when developing in dbt. A data team should use these three environments:
- Production: The source of truth, where the data users and BI tools consume the data from.
- Development: A sandbox where each analytics engineer can prototype and validate their work (typically in their named schema e.g. dev_gleb).
- Staging: An environment created during the deployment process mimics Production, but is intentionally separate to allow testing before the changes are deployed. Not every organization will have these exact names for their environments; we’ve seen organizations where instead of a schema per developer, it’s a schema per PR. At the end of the day, what matters is separating out production data—the bloodline of your company—from data that is still under development or untested.
But why do you really need different environments? Couldn’t you just create a **test_dim_orgs **table in your production database? A few reasons you don’t want to do that:
- It’s not scalable. Soon it becomes test_dim_orgs_1, test_dim_orgs_2, and creates a disorganized and ungoverned mess in your production database. In addition, it’s not clear who made these tables, why they exist, and what their purpose is.
- You don’t want bad or untested data working its way into your production data. Your BI tools, data apps, and machine learning models often read directly off of production data, and the risk of introducing bad data in an environment like that can have real impact on your data and business. If business user A has access to query your production data, but doesn’t know the ins-and-outs of your production database set-up, they could easily accidentally query the dev version of a table.
- Your data team members need their own dev spaces, so they can tinker with the SQL that works, make changes without introducing risk into production, and create safe environments for them to do so.
Anatomy of an effective CI pipeline
The CI process is commonly referred to as “CI pipeline” since it usually includes several steps chained together. For analytics or data engineers, their CI pipeline will typically contain 4-5 steps:
- Running dbt compile
- Building your dbt project in a staging environment
- Running foundational dbt tests
- Running a SQL linter
- Running robust testing suites like Datafold
1: Run dbt compile
dbt compile can be helpful as an automatic check for valid Jinja and SQL syntax and would catch missing dependencies, such as missing packages. This is your first test to make sure your proposed code changes don’t fully break your dbt project.
2: Build the project in a staging environment
The most important step. This likely means executing dbt run in a separate staging environment and builds data produced by the new code. If the code can’t successfully compile or write data to the warehouse, you’ll know here.
3: Run dbt tests
dbt comes with a simple yet powerful framework for writing assertions about data. These tests validate essential assumptions about the data, such as the uniqueness of primary keys, checks for null values, and proper ranges for metrics.
While you and your team members can run tests as they develop at any time, and you can also run dbt tests as part of the production run, none of those instances help prevent bad deployments. Tests during development can be simply skipped or forgotten about, and tests in production are too late. If it fails in production, someone has likely used bad data already.
4: Run a SQL linter
SQL linters such as SQLFluff help maintain codebase readability, which becomes especially important as the team and the project grows. Using a SQL linter enables you to set and enforce standards for your code’s structure and eliminates unproductive back-and-forth about style and conventions during code reviews.
Your future team members are begging you, *please *use a linter in CI.
5: Bonus points: Run additional data tests like data diff
An additional step during the CI process is to run more data quality tests for your PR. At Datafold, we support testing that allows you to compare (what we call diffing) your dev and prod versions of the tables you’re changing with your dbt code updates.
Data diff can be plugged into your CI process to show the impact of the proposed code change on the data by comparing the data in staging and production environments. Running data diff in CI has the following benefits:
- Allow code reviewer to immediately see the potential impact of the code change on the data (ex. Are there different numbers of rows or primary keys between dev and prod versions of dim_orgs? Did any row values have an unexpected change in value?)
- Provides visibility into the downstream impact – how are dependent dbt models and metrics potentially impacted by this change?
How to set up CI for dbt
To set up CI for dbt, it’ll look a little different depending on if your team uses dbt Cloud or dbt Core.
For dbt Cloud users, it’ll take a few simple steps to set up CI for your dbt project:
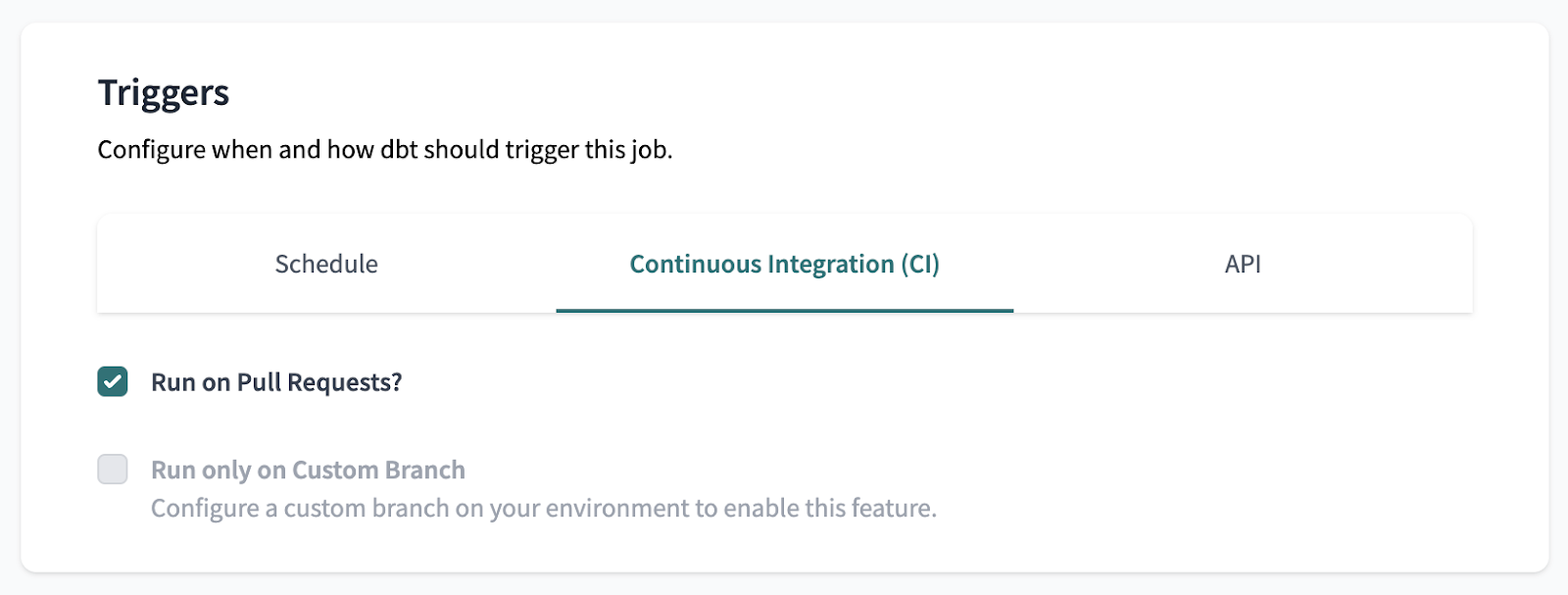
- Set up a new dbt Cloud job in CI – do this within the dbt Cloud app using the following details:
- Add your dbt commands (typically dbt build or dbt compile, dbt run, and dbt test) that you want ran during this job
- Defer to a previous run state (your production job—this tells dbt Cloud where to find your prod data to test and compare against)
- Ensure that this job is triggered by “Run on Pull Requests” in the job’s settings
💡 Bonus points💡 Use dbt Cloud’s Slim CI to run and test only modified models by enabling dbt build —select state:modified+ in the dbt command section of the PR job. This makes it so only modified models and downstream modified models will be run and tested during CI (gotta save that time and $$$). To read more about how to do this, check out the step-by-step guide to getting started with Slim CI in dbt Cloud.
Because each dbt Core set up is a little different, setting up CI can vary depending on your dbt project structure and git provider. In general, you can create GitHub Actions that implement the following:
- Run production dbt models on a schedule
- Build, test, and diff dev changes in a staging environment
- Upon PR merge, build PR code changes in your production environment For a more in-depth guide to getting started with CI using GitHub Actions and dbt Core, check out this tutorial.
Wrapping it up: Benefits of CI in analytics work
Implementing continuous integration for your dbt project is one of the highest ROI tooling and process improvements you can do for your team. The benefits of implementing CI include:
- Accelerate the velocity of your team by making code reviews more informed and thus easier and faster to perform.
- Ensure stakeholder trust in data by reducing the number of bad code deployments that break data.
- Enable better collaboration by making it easier for everyone to contribute to the dbt project regardless of their skill level and domain knowledge with automated testing and enforced code standards.
- Improve your team’s quality of life. Validating and reviewing code is hard, and rolling back changes and firefighting incidents contribute to burnout. So, we hope we convinced you to implement CI in your dbt deployment workflow! To learn more about CI, how to implement it for your dbt project, and general best practices around data deployment, check out the following resources:



