

When it's time to level-up your dbt tests: 5 reasons to consider adopting data diffing
When you've done all your data tests and data quality issues are still happening, what's happening? We unpack why these issues happen and how to know when it's time to evolve the way you test your data.

At Datafold, we personally know the pains of data quality mishaps. Back when our CEO was a data engineer at Lyft, he introduced a small code change that led to literally thousands of inaccurate dashboards at the company and brought hundreds of meetings and workflows to a halt. I’ve unknowingly introduced data quality issues with code changes–despite all my dbt tests passing and PRs getting approved–leading to many frustrated stakeholders and job security anxiety. And I’ve yet to meet another data practitioner who hasn’t intimately felt the fear of introducing incorrect or breaking data with their code change.
So what is it about our current data quality testing methods that are failing us? In this post, we’re going to walk through five common pains felt by data teams, and address why they’re signs to evolve the way you test your data. If:
- You’ve experienced a major (or several major) data quality issues…leaving folks stressed, unhappy, or in deep trouble.
- You’re testing your data the way you’ve been taught, yet end business users are still finding numbers that don’t make sense.
- Your business, data, and team are growing faster than you can imagine—and following best practices is becoming harder to do at scale.
- As a result of these factors, your dbt development pace is slowing down and oftentimes feels completely bottlenecked.
- Last but certainly not least, all of these pains culminate into a truly people-centric problem: your business and end users not being able to trust the data or your team. …keep on reading. Let’s break down why so many data teams feel these pains, and how data diffing and Datafold are offering new solutions to these timeless problems.
💡 A note: If your team is experiencing some (or maybe all) of these pains, it’s not because you’re a “bad” data practitioner. These pains are common; these pains are universal. We know that so many data issues feel like (and often are) out of our control. At Datafold, we want to create a world where practitioners regain control of their data and are enabled to focus on the work that matters: delivering high quality analytics to the business.
1. You’ve experienced a major data quality issue
It only needs to happen once—a data quality issue that leads to hundreds of broken or inaccurate dashboards, an angry C-suite, and potentially (depending on your industry), some serious legal repercussions. An incident (or series of incidents) like this will immediately decrease the trust of the data (and the data team) to the business.
If you work in an industry like financial services or healthcare where high quality data is not just a nice-to-have, but a must-have, these types of data quality issues could have impacts that lead to job loss, lack of compliance, or serious regulatory problems.
2. You’re testing your data, and yet data issues are still slipping through
You’re doing everything right! (Or so you think.) Your current development workflow probably looks a little like this:
- Make some models changes in your dev environment
- Run your foundational dbt tests to make sure everything passes
- Maybe write some manual queries to check that row counts and values look generally right
- Open a PR for review
- PR reviewer sees that dbt tests pass in a CI test or they trust your word that everything was ok and you get that “LGTM 🚀”
- Branch gets merged in And yet, business user A complains that the numbers “look off”, or data that was previously there is now missing. How is this possible? You did everything right.
Most of the common data quality tests—assertion-based tests like dbt and unit tests—test for things you predict will be (and must be) true: primary keys are unique, ARR values are non-null and greater than zero, etc. What these tests don’t test for is the unexpected and unforeseen changes, such as:
- How does this code change impact the value of the individual rows? E.g. There’s no dbt test that checks for a changed first_name value (like from ‘Brittany’ to ‘Britney’) or a slightly different event_timestamp
- Will any primary keys be missing as a result of this code change?
- How does this code change impact the number of actual rows?
- Were any columns removed or added unexpectedly? Traditional data quality tests are giving you the foundation of what must be true, but don’t tell you how the data itself is changing with your dbt model updates.
3. Your data, team, and business are growing in scale and complexity
If you adopted dbt and modern data stack (MDS) technologies as early as 2016 (or even in the past two years), your dbt project has likely grown to hundreds if not thousands of models. Your data (and cloud warehouse costs) have also increased beyond expectations. At this scale, data modeling becomes more complex, small code changes start to have a heavier impact on the underlying data, and scrutinizing model changes becomes the norm.
As a result, your world might look a little like this:
- PRs take days (no longer just hours) to review
- You struggle to wade through data test failures—what’s noise and what’s actually important?
- Making changes (even small ones) to your dbt project is intimidating because of the potential large impact on hundreds of downstream models or data apps This level of scale causes delays in dbt development and alert fatigue from the onslaught of model or test failures, and creates a situation where it’s regularly difficult to maintain and grow your dbt project.
4. You’re experiencing bottlenecks in your dbt development speed
All of it—the manual tests and lengthy code reviews, complex PRs, and reversal of merged PRs—delay the data team’s ability to release necessary code changes. When your team is afraid of making code changes because of the potential to introduce drastic data quality issues, your team is stuck. Your dbt development slows down. The backlog of data requests grows. Existing data tech debt remains unsolved (and continues to expand). And your team stops delivering analytics work in a timely manner.
5. Your data team struggles with developing and maintaining the trust of the business
Sum all of these pain points up and you’re left with business users that are confused and frustrated with inaccurate data, slow turnarounds for data requests, and a lack of transparency into what’s going on. We know how hard it is to gain the trust of the business, and even harder to maintain it.
When users don’t trust the data and stop coming to the data team when they need support, they start building and hacking their own solutions. In this world, data teams lose the ability to govern and know about data solutions, data quality becomes blurry and essentially unknowable, and the value (and investment) of data teams becomes questionable.
How data diffing and Datafold are empowering robust and proactive data quality testing
If you’re experiencing any of these pains, you’re not alone! This is why we created open source data-diff and Datafold Cloud, to introduce a new, more robust way of testing your data. With data diffing—a proactive data quality testing method that builds on top of your dbt project—you find data quality issues before they enter your production environment.
What is data diffing?
Backing up a bit, what the heck is a data diff?! In plain terms, a data diff is a comparison between two tables that checks whether every value has changed, stayed the same, been added, or removed. It’s just like a git code diff, but for the tables in your data warehouse. In Datafold, diff results between a staging and production table look a little like this:
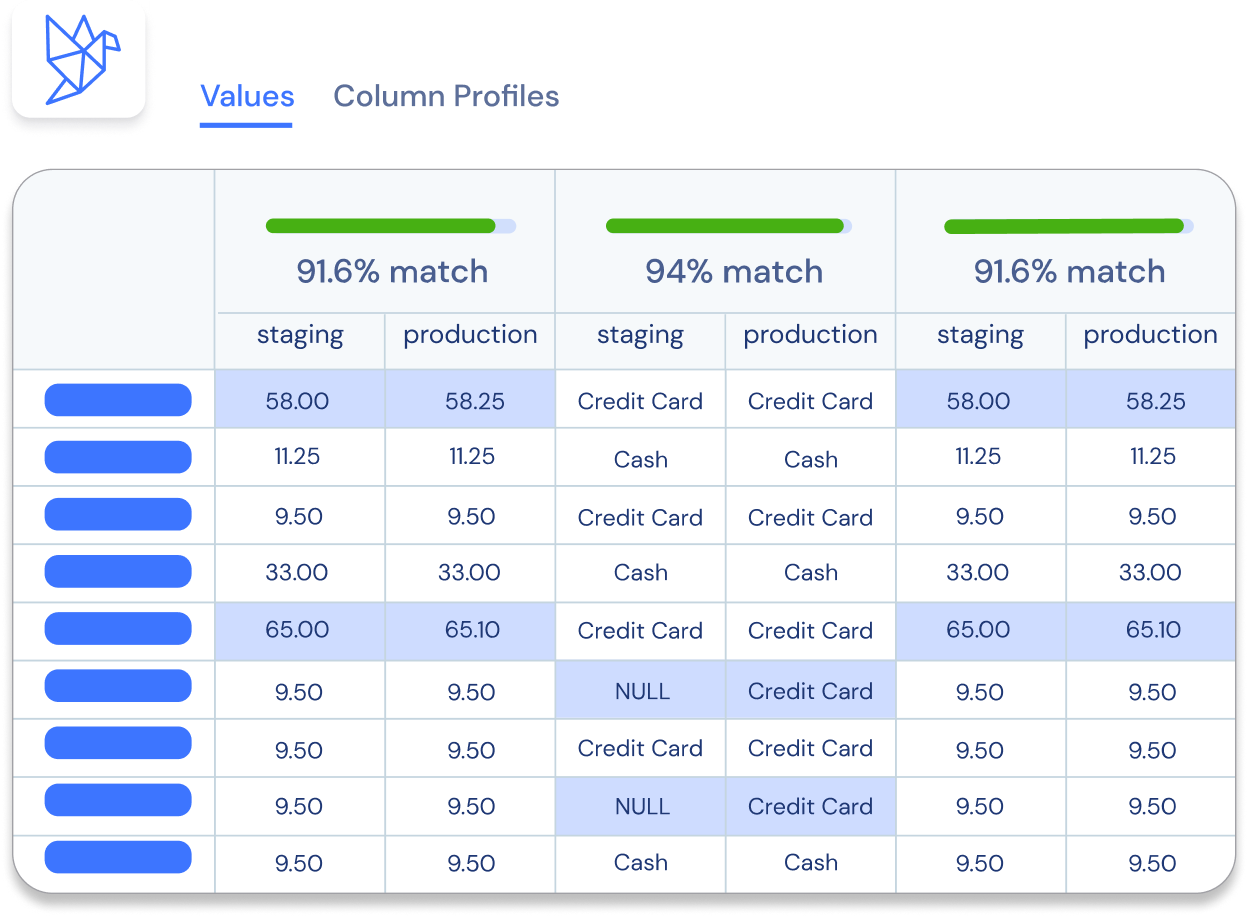 In this diff, you can see how each column’s individual rows may change between your staging and production environments for a given table. Using Datafold Cloud, you can perform quick diffs across your dev and prod environments for your dbt models.
In this diff, you can see how each column’s individual rows may change between your staging and production environments for a given table. Using Datafold Cloud, you can perform quick diffs across your dev and prod environments for your dbt models.
When you diff your data, you know exactly how your data will change with your proposed code changes. When you know exactly what type of impacts your code changes will have on production, developers:
- Work with more confidence and speed,
- Development bottlenecks are removed, and
- Data quality issues are found before they enter production.
What does diffing look like in practice?
At Datafold, we believe that data diffing should be utilized in two core places in your dbt lifecycle: development and deployment.
-
During development: While you’re developing your dbt models, run your core dbt tests and diff your data to speed up your development work. This gives you your initial confidence in your PR.
-
During deployment: Testing during development is a great way to proactively find issues, but diffing during deployment automates testing and guarantees issues don’t slip through. By using Datafold Cloud’s CI diff check, you can see immediate diff results and impact analysis of your code changes within your PR, so you and your team understand how your code changes will affect downstream dbt models, BI tools, and other data apps. As a result, only approved data differences make it to your production environment.
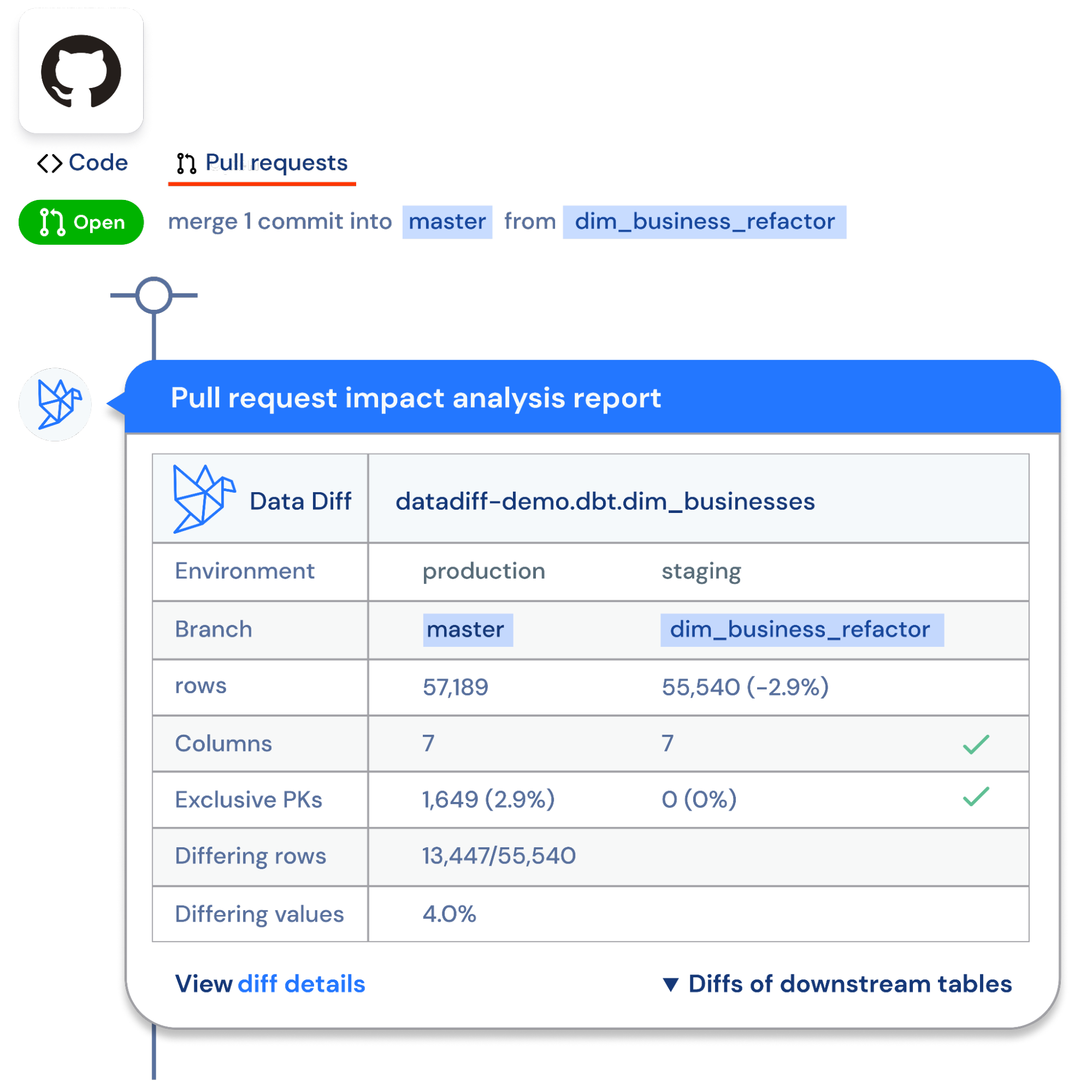
So, is it time for you to start diffing?
All of this is not to say to abandon your dbt and other package tests; in fact, it’s the opposite. At Datafold, we believe diffing is most powerful (and data quality is the highest) when it builds off of your existing data quality foundation.
So yes, if you’re experiencing any of the pain points we talked about above, it’s a good idea to consider evolving your data quality testing workflow. Run those unique and not-null tests, but pair it with data diffing and Datafold to truly understand the underlying data changes and downstream impact of your code changes. If you want to learn more about data diffing, Datafold Cloud, and automated proactive testing, check out the following resources:
- 📖 What the heck is data diffing?!
- 📺Book a demo to see Datafold Cloud live in action! Happy diffing!



