

Tips for getting the most out of your dbt Cloud setup
So you want to learn more about dbt Cloud? Go through all the tips, tricks, and best practices to ensure your team is leveraging all dbt Cloud has to offer.
How many times have you had to run dbt models locally because your orchestration tool of choice wasn’t allowing you to unlock the full power of dbt? I’ve experimented with all different types of tools for running my dbt models; some are great in areas like handling dependencies and others are great in their monitoring capabilities. However, there seems to always be something missing.
Luckily, dbt Cloud exists to handle the unique features of dbt while orchestrating models in a way that’s reliable and transparent. I’m sure there’s a lot of great features you already know about, like how dbt Cloud handles tests and allows you to develop directly within their Cloud IDE, but I guarantee there’s a whole world of features you have yet to unlock. Let’s dive into them.
dbt Cloud job notifications
Notifications allow you to send important alerts to whatever platform you check most often (email or Slack), rather than having to open the dbt Cloud UI every time you want to monitor a dbt Cloud job run.
If you use Slack for internal communications, it’s best practice to send these types of notifications to a data alerts channel (ex. #alerts-dbt-cloud) that includes all data team members and maybe even some business users that regularly use your data products. This increases transparency into the data pipeline reliability and helps let everyone know if there are data quality issues or delays in data freshness.
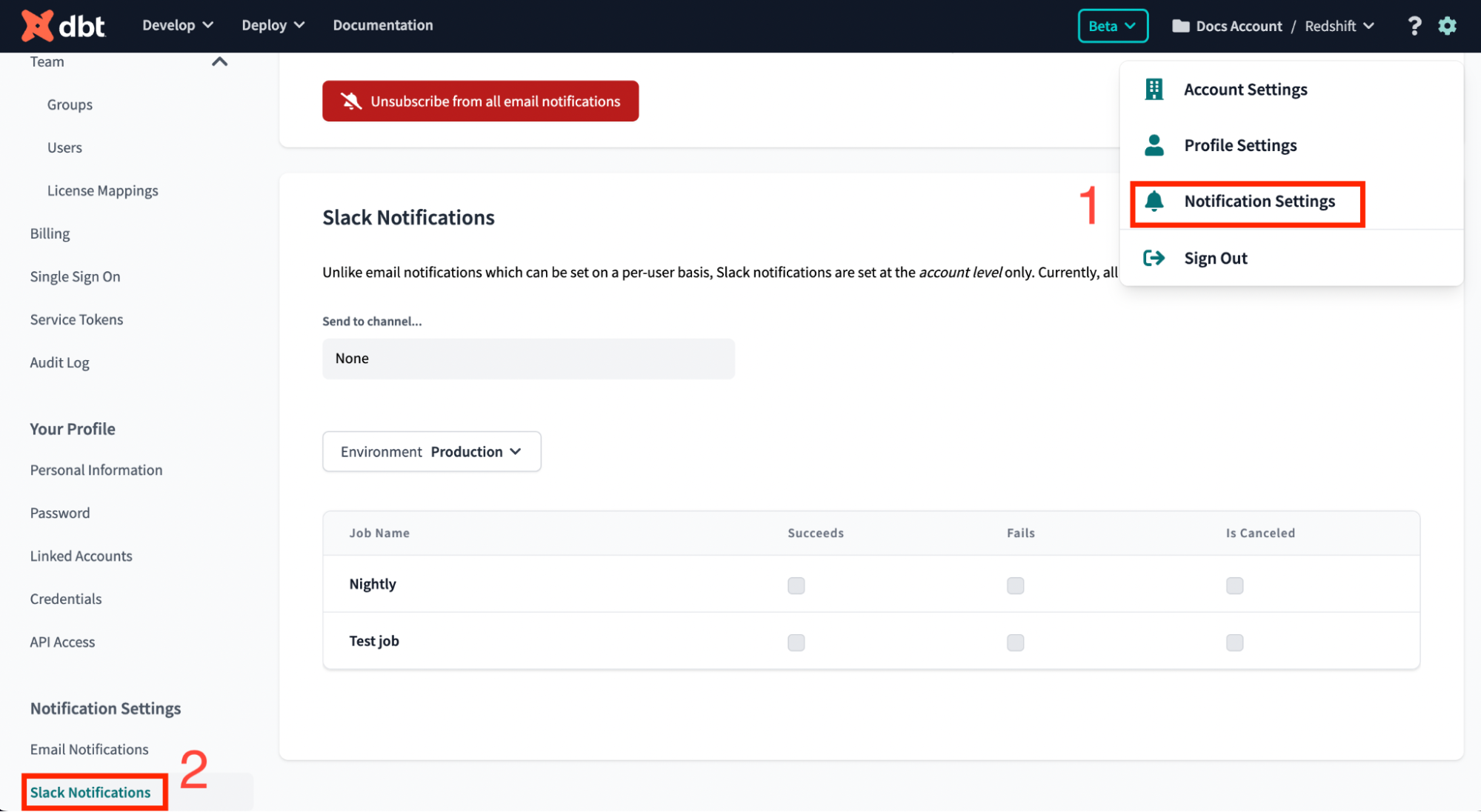 dbt Cloud also allows you to customize these notifications for the environment (do you want alerts for only prod?) and the type of run (do you care about successes and cancels? Or only failures?). This way you aren’t cluttering the Slack channel or your inbox with alerts that aren’t important. I recommend setting these for only production failures in order to prevent alert fatigue.
dbt Cloud also allows you to customize these notifications for the environment (do you want alerts for only prod?) and the type of run (do you care about successes and cancels? Or only failures?). This way you aren’t cluttering the Slack channel or your inbox with alerts that aren’t important. I recommend setting these for only production failures in order to prevent alert fatigue.
Hosting and sharing documentation
If you’re familiar with dbt Core, then you probably know the dbt docs generate and *dbt docs serve *commands, which generate an interactive UI for your dbt project’s documentation. The docs site allows you to see your project’s DAG, column and table definitions, and tests in one readable location.
However, when you generate dbt Docs locally, you still need to host them somewhere to make them usable and viewable by other people in your company. If your dbt Docs are not self-hosted somewhere (such as in an S3 bucket or on a service like Netlify), it can be difficult for less technical data analysts or business users to maneuver a local dbt Core development to access the docs site. These users are often the folks who need this documentation the most, making the lack of hosting an inconvenience for the entire team.
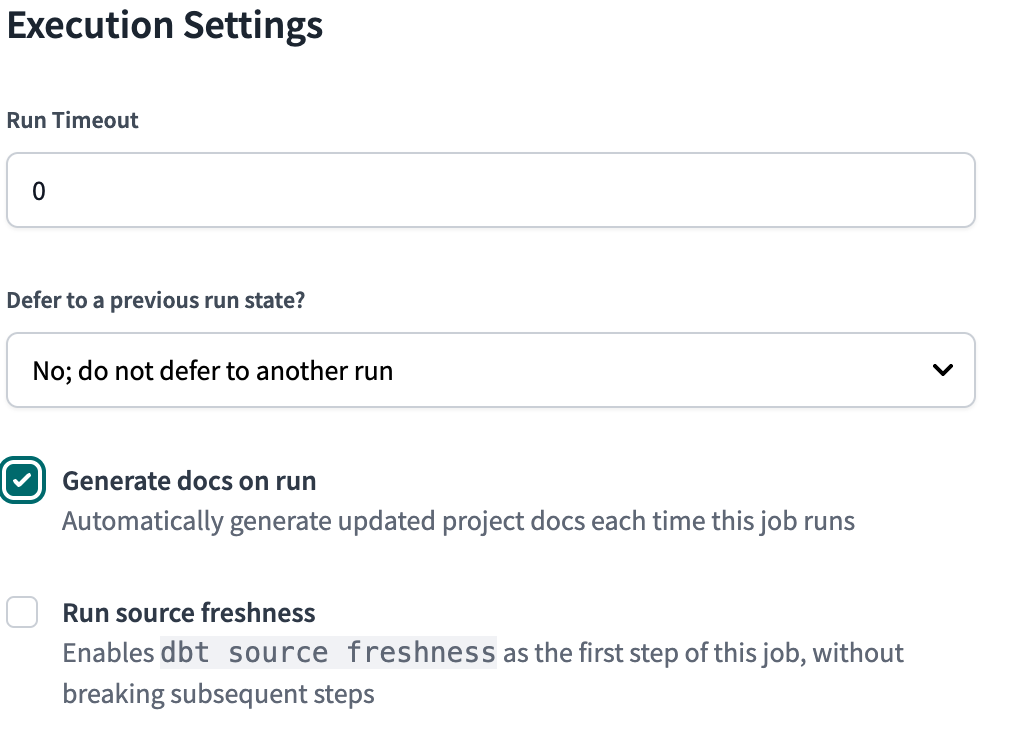
Luckily, with dbt Cloud, the docs site is automatically hosted for you, making it available to any user who has access to your account. When you select “generate docs on run” on a job in dbt Cloud, your project’s docs are automatically updated on the UI.
 Data teams also have the capability to create read-only users in dbt Cloud who have access to documentation and source freshness reports, but not development access via the dbt Cloud IDE, allowing them to govern access as needed.
Data teams also have the capability to create read-only users in dbt Cloud who have access to documentation and source freshness reports, but not development access via the dbt Cloud IDE, allowing them to govern access as needed.
dbt source freshness
dbt Cloud makes checking for source freshness a breeze. Using the dbt Cloud job job scheduler, you can enable source freshness checks as the first stop of any job run. However, if one of these checks fails, it will not necessarily cause dependent models to also fail (depending on the warning and error thresholds you set for each source).
While this may sound counterintuitive, a source freshness check can be helpful for ensuring all of the most important models still run. A lot of times I will have one source fail and don’t want every other model in the job to fail with it. If a key data model doesn’t run because a freshness test failed the entire job, this causes delays in refreshing important data models that are used by the business.
However, if the freshness of a source is critical, you can still create a separate job to check for source freshness only, or even add the dbt source freshness command to your job. Adding it this way will ensure dependent or downstream models aren’t built if freshness standards are not met.
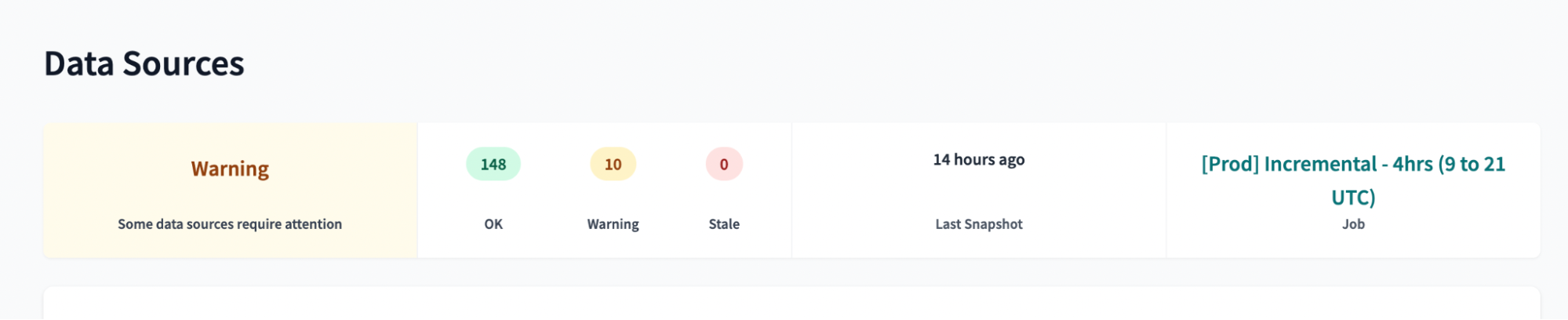
dbt Cloud additionally supports an intuitive UI for source freshness, allowing you to quickly identify data sources that are within and outside of your freshness standards.
Adding continuous integration (CI) to dbt Cloud
One of my personal favorite features of dbt Cloud is the ability to merge it with your git pull requests. With dbt Cloud, you can test your pull requests before merging them, seeing whether your jobs will build and run successfully and if tests set in place continue to pass after updating the code. This feature has saved me from making a countless number of mistakes in production!
 Rather than running your entire data environment, you can choose the slim CI version which only runs the models that have been changed in the PR. Under the hood, dbt uses the dbt run —select state:modified command to do so. This way, you’re saving on costs and resources by only running and testing modified models.
Rather than running your entire data environment, you can choose the slim CI version which only runs the models that have been changed in the PR. Under the hood, dbt uses the dbt run —select state:modified command to do so. This way, you’re saving on costs and resources by only running and testing modified models.
This is a foundational data quality check that can prevent a lot of problems in production. dbt Cloud’s slim CI in combination with a tool like Datafold will ensure you are always producing accurate and reliable data. Not only can you check dependencies between models, but you can use Datafold’s CI integration to check the data-specific outputs of your code changes like row count, primary key differences, and more.
dbt model orchestration
dbt Cloud offers a few different options for running or orchestrating your dbt models. They include:
- Running now
- Scheduling with cron specification
- Event-driven triggers The** run now** option allows you to run your data models on the spot. While this isn’t a best practice to do all of the time, it comes in handy when trying to debug an important model and get it back up and running quickly. For example, I use this a lot when Redshift prevents multiple models from running at the same time and one needs to be re-ran immediately, so the business can have fresh data.
The most popular method for running and orchestrating data models using dbt Cloud is the dbt Cloud scheduler that allows for cron specification. This allows you to choose a specific time and cadence that you want your dbt Cloud job to kick off. You can choose to do this at one set time for daily models, or even every hour for models that need to be run more often. I often like to use dbt tags to schedule time-based models together (ex. [‘weekly’], [‘daily’], [‘hourly’]), so I don’t have to create specific dbt run -s for each model that needs to be run at a specific interval).
While this is a popular way to orchestrate models, it also has its limitations. Models that depend on one another might run at the same time, causing data to be stale. External tools that depend on these models may run into issues if these models take longer than usual to run. When you use cron scheduling, jobs run no matter the behavior of the models before it, which can cause a cascade of errors.
Fortunately, dbt Cloud has built-in mechanisms that prevent two jobs from being run at once. This helps to avoid collisions in the same model being built at the same time.
Lastly, dbt Cloud allows for event-driven job triggers, such as when a PR is opened kicking off a CI job. Currently, dbt Cloud does not yet allow for triggers based on other jobs, models, or external tooling.
Webhooks in dbt Cloud
If you have yet to utilize dbt Cloud’s webhooks for your complex models, you’re probably missing out! Webhooks allow you to send events or notifications about your jobs to other external systems such as Microsoft Teams or Slack. They act as a communication system between two web applications, replacing the constant polling of external APIs.
dbt Cloud webhooks work with BI tools like Tableau and Mode as well as data monitoring tools like PagerDuty and Datadog. If you use data apps like these, dbt Cloud is able to handle external dependencies, such as only triggering external jobs like dashboard refreshes or data quality checks when dependent models run.
Configuring webhooks on dbt Cloud is relatively simple. You only need five parameters—a name, description, an event to trigger the webhook, a job the webhook should trigger on, and an application endpoint. When a webhook is triggered, it will send a JSON payload to the specified application endpoint. This application then receives the data you’ve sent over from dbt, integrating it to use downstream from your models.
Permissions
dbt Cloud makes it easy to maintain a secure and governable data environment due to the different access features they offer. With dbt Core this can be more difficult due to the manual nature of the profile.yml file that is set up with access credentials.
dbt Cloud allows you to purchase both development and read-only users. Read-only users are great for business stakeholders who want to access the documentation hosted on dbt that we discussed earlier in the article. This way, they can see all of the documentation of data sources, data models, and their fields. However, they can’t accidentally make changes to important jobs or transformation code used in models. Read-only users are also great for data analysts who need to check the status of certain data models used in their dashboards, but may not actually have any experience or need of creating dbt models.
dbt Cloud also allows you to control the access of those with developer accounts through the use of groups. A group is a collection of users who inherit the permissions assigned to that group. Groups allow you to easily assign users the correct access permissions without assigning each permission individually.
For example, I could create a group called “Analytics Engineers” that has permissions to read and write from both dev and prod environments, but only read from raw data sources. Then, whenever a new analytics engineer joins the company, I can assign them to that group rather than assigning each permission to that user.
Unpacking dbt Cloud metadata with the Discovery API
dbt Cloud offers a newly reimagined Discovery API which allows you to utilize specific metadata about your dbt project and its runs. Having this metadata available can help you with more custom development such as complex alerting systems or model run-time optimizations.
dbt also emphasizes the ability to closely track data quality using this Discovery API. Using the Discovery API, you now have the ability to answer questions like: who is responsible for this failure? Who was granted access that they shouldn’t be? Instead of manually searching around for these answers, you can quickly get these answers by calling the Discovery API.
This feature is particularly helpful for larger development teams with complex systems. Oftentimes, larger teams need more customization to get what they need out of tools. The Discovery API allows them to do just that by making all of dbt Cloud’s metadata available at their fingertips.
dbt Cloud Semantic Layer
The Semantic Layer in dbt Cloud allows you to define metrics* *that are used repeatedly in the business and query those values in different end applications (e.g. BI tools, data cataloging tools). The primary goal of the dbt Cloud Semantic Layer is to solve the problem of multiple metric definitions existing across different teams and create a single source-of-truth for core business metrics. For example, the marketing team may define revenue as income minus cost of goods. However, finance may only count revenue for orders that have already been shipped. In this case, there is an additional filter from the finance team that the marketing team is not aware of, leading to potential (and drastic) differences in this key value.
If we look at how a metric is defined in the semantic layer, you can see a clear description, calculation method, expression, time grain, and dimension.
By having these metrics defined, business teams can compare their definition of a metric to another teams’ definition. In addition, by querying these metrics via the dbt Cloud Semantic Layer, this helps to create a single source of truth for metrics within the company, increasing overall data quality, consistency, and accuracy.
It’s important to keep in mind that the Semantic Layer can only be used with dbt Cloud (not with dbt Core). While you can apply the same idea in Core, you need to create your own calculations whereas in Cloud these aggregations and grains are automatically applied with the *metrics.yml *file.
Making the case for dbt Cloud
dbt Cloud is a powerful tool to use to schedule your dbt data models, helping you increase data quality with each feature you enable, such as the Semantic Layer, testing, or webhooks. By using dbt Cloud, your team can thoroughly document and develop your dbt project, share it with teams in a secure way, and standardize data across different teams. In addition, dbt Cloud enables developers to properly test the models they are building and create more complex applications and pipelines using features like webhooks and continuous integration.
All of these features of dbt Cloud help you to produce more accurate and reliable data for business users—but it can’t do it alone. Using your git provider of choice to version control your code, Datafold to proactively monitor changes in your data due to code changes, and dbt Cloud to deploy your models, your company is set up with a powerful stack to help it accomplish its data-driven goals.



