

Data Quality In Data Engineering Workflows
Learn what steps your team needs to take to improve data quality and get the most out of your data.

Data quality testing: we all recognize its importance, but sometimes have trouble figuring out exactly how it manifests itself in data engineering workflows. Ingraining data quality within CI/CD and ongoing data modeling will ensure notification upon data quality drift.
Why invest in automated data testing?
Software engineers test the applications they build, why wouldn’t data engineers test the data they produce?
The answer is that data engineering is undergoing a new wave, where data professionals finally have tools actually enabling them to be better engineers. Just because they haven’t invested the time previously, doesn’t mean they shouldn’t. In many organizations, data (or more recently “analytics”) engineers are the gateway between the raw data and the data application. This framework is in place to ensure data that is exposed to the rest of the organization via BI is clean and accurate. Without automated data quality checks, it is impossible to guarantee the data stays in the same clean state over time.
Automated data tests give data teams confidence by notifying them if there is accuracy drift.
The data engineering workflow
You’re a data engineer and get a request to add a field to a data model.
You implement it, run the code to ensure there aren’t syntax errors and do some very basic checks on the output (for instance, making sure everything isn’t null). Hopefully your team has some sort of version control tool like Github so you open a pull request for another data engineer to review. It’s approved, merged, and you move on. Sound familiar?
Well, there are several inherent problems with this framework:
- First, the checks on the output are determined by the coder at a point in time, decisions which are extremely subjective and subject to miss something important.
- Second, the lack of ongoing testing post-merge creates an area for accuracy divergence.
- Third, a lot of time is wasted doing these checks manually, not to mention all the time to investigate and subsequently clean up a mess if an incident were to occur.
Data is constantly changing, which means there’s always going to be new data to QA. Without an automated tool, ensuring quality is unsustainable. These two areas of data quality vulnerability can be alleviated by leveraging automated data testing paradigms in both your CI/CD framework (to test changes to the code that processes the data) as well as during regular data workflow orchestration (to test the data as it changes with new raw data coming in).
So, you might think the time is something you’re willing to invest. What if I ask the same question during a time crunch to get out an important report?
I’ve seen time and time again the manual data quality checks be the first to go in a high stress situation, but the importance of testing should increase with the importance of the output data. Having more automation in the development pipeline gives your team the momentum needed to not surpass this step under pressure.
Automated data testing: CI/CD
Taking a step back: what is CI/CD?
CI/CD stands for continuous integration and continuous delivery. The premise of CI/CD is to allow development teams to implement new code iteratively, integrate new processes into existing ones automatically, and make sure that all steps required testing and deploying are always performed.
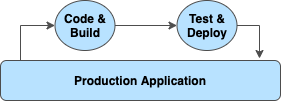
Tools like Github enable version control by allowing multiple contributors to submit changes for review by team members (pull requests, or “PRs”). CI tools like CircleCI sit on top of Github to trigger certain processes automatically when a PR is put up for review.
For example, upon any changes to the main branch running existing code, the CI system could trigger a build or deploy to update the production application with the new changes. This obviously requires some upfront configuration, but makes changing important processes well tested and seamless.
You might ask how this relates to data quality: let’s talk about updating code for a data model.
As mentioned, this can be done in the form of submitting a PR in code for someone else to review. The question at stake: how can you be sure the effects of the change are fully understood?
CI/CD tooling doesn’t have to be limited to triggering updates or checking for syntax; it can serve as an important layer for data quality.
CI can be a data engineering tool, too. Imagine this: your organization has a separate staging environment where data engineers can test queries before having others review. Before you submit a pull request, you implement the change in staging. Upon actually opening a pull request, a data engineering “build” is triggered: the build serves both software and data engineering purposes.
The build would include several checks, but notably generating a comparison of staging and production datasets for the table that was modified. Let’s call this generating a “data diff”.
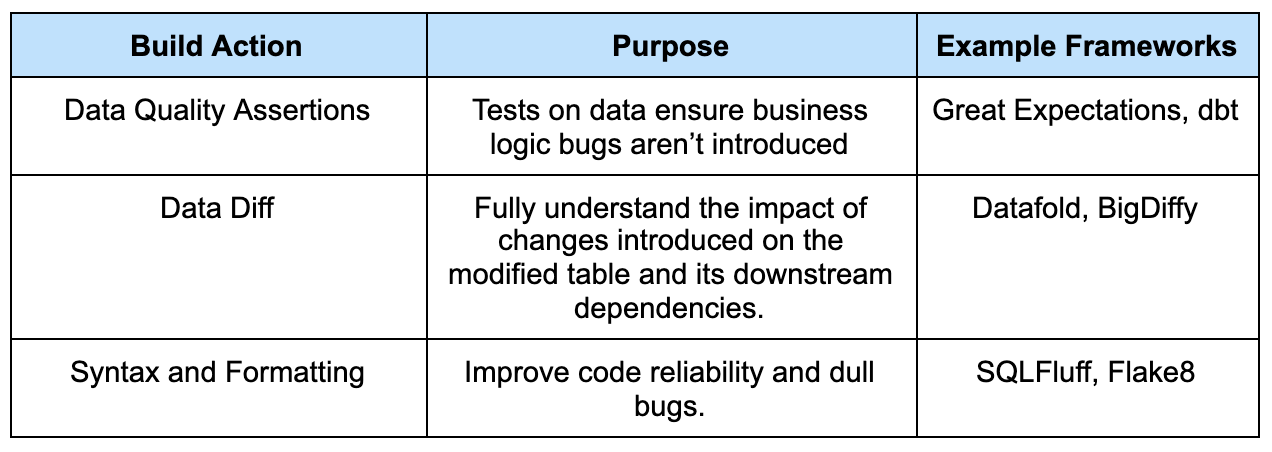
Data assertions make sure the inherent data trends didn’t change in an unexpected way; if you use a data testing tool like Great Expectations, the build could run those tests in staging to ensure what you expect of your data is still intact. Some assertions could include checking the number of rows on a table, or the percentage of a column that’s null; example documentation and validation is pictured below. Similar tests can be implemented directly within a dbt framework as well.

Data diff inherently involves business context to understand if the changes make sense. How can datasets be compared holistically? The data diff should be configured in such a way as to provide an analysis of the dataset from different angles. Some basic comparisons such as the number of rows that changed and the total row count if different will inform on general table metrics. Comparing row-wise by joining on the primary key would allow for a more detailed comparison.

Lastly, the syntax and formatting checks are applicable in the data engineering world as well. I can’t emphasize enough how important consistency and readability are in code when scaling a team. These can be run by the person coding, but that can be easily forgotten; if these checks are integrated into the development pipeline, they’re automatic and just a part of life.

All of the build actions can be done manually but is prone to error as the task is inherently manual. When making a change, I’ve had business stakeholders often ask why a certain metric is now different. Instead of guessing that it was due to a recent change, knowing it was due to a change instills confidence from the business in the analytics department that there wasn’t unintended behavior introduced.
Automating checks as well as staging and production environment comparisons decrease the chance of pushing changes into production with unknown consequences. Surprises aren’t a good thing when making important changes.
Automated data testing: Workflow Orchestration
Now the new code is in production. Your data models are updated. What next?
The testing doesn’t end after the changes are part of the main workflow. The primary difference between testing applications and testing data is that data always changes and relies on many more upstream processes. I mentioned Great Expectations and dbt above – let’s dive into when to trigger these tests.
A comprehensive data quality testing layer will ensure quality data products no matter what upstream changes occur. Data models are usually updated on a schedule; usually, after the scheduled update the data is retrieved from the data warehouse by the BI tool to update dashboards. The key to quality data products: gating dashboard updates behind automated tests. This ensures BI data is updating if and only if the data meets preset expectations.
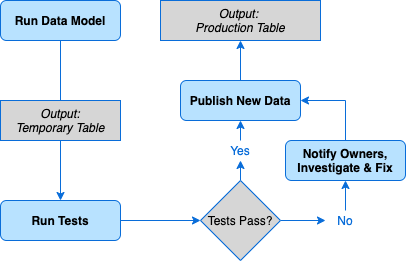
Let’s say the BI tool pulls data from table_a. If you update this table directly and run tests, even if the tests fail, the new data will still be pulled into dashboards which is exactly what the tests are trying to prevent.
Instead, the solution is updating the data and pulling the new dataset into a temporary table, running tests, then upon them passing updating table_a* *and removing the temporary table. If the tests fail, the pipeline should be blocked: table_a won’t be updated and the temporary table won’t be deleted. In this case, reporting does not update with inaccurate or unexpected data while the temporary table persists to debug the issue.
The key to keeping dashboards accurate is gating updates to production data behind tests. In truly data-driven organizations, I’ve seen business units make impactful financial, marketing, and product decisions based on the output from the analytics team. If the data were inaccurate, the decisions could have been the wrong ones. If the analytics team builds confidence in their output throughout the organization, there is instilled confidence in decision making.
Final thoughts
Data testing serves as a gate: a gate that ensures only clean and accurate data gets through to the dashboards that drive decision making.
Any manual steps are prone to error, so I suggest automating as much of the data testing process as possible. From generating data diffs between staging and production environments to running tests in the data modeling workflow, automation results in less work for the data engineer and higher reliability.
The data testing gate instills confidence both within the analytics team and throughout your organization.
Photo by Nicolas Thomas / Unsplash



