

Uncovering Apache Airflow's 3 most underused features
Uncover the potential of Apache Airflow's most underused features: User-defined Macros, XCom, and Task Sensors, to elevate your data pipeline efficiency.

Apache Airflow is one of today’s most popular data pipeline orchestration frameworks. Despite its widespread adoption, we’ve noticed that many teams overlook some of its more useful features for everyday development. This article will tell you what these features are, why you should use them, and provide examples to help you get started.
User-defined Macro
What is it?
In Airflow, you can parameterize your data pipelines using a combination of Variables and Macros. For example, if your job is scheduled to run daily, you can use the ds variable to inject the execution date into your SQL:
SELECT * FROM table
WHERE created_at = '{{ ds }}'When this query is rendered in an Airflow Task, Jinja parses the curly braces and resolves any variables or macros contained therein. There are some pretty useful macros available right out of the box. For example, ds_format takes as arguments a date-string, an input format, and an output format, and returns a new date-string:
SELECT * FROM table
WHERE created_at_month = '{{ macros.ds_format(ds, "%Y-%m-%d", "%Y-%m" }}'However, the number of built-in macros is rather limited. You’re bound to need more functionality. Enter the User-defined Macro.
Coding Example
You can add User-Defined Macros when instantiating your DAG:
Now, the quick_format function can be used anywhere you would normally use a macro:
This feature can help you build powerful, dynamic parameterization in your DAG. Perhaps you need to change the timezone of a date-based file path using the pendulum library. Perhaps your query needs a different WHERE clause every day of the week, and you don’t want to maintain seven SQL files. In either case, User-defined Macros provide an elegant solution.
from datetime import datetime
from airflow import DAG
# Define a custom macro!
def quick_format(ds, format_string):
ds = ds.strptime('%Y-%m-%d')
return ds.strftime(format_string)
# Instantiate your DAG
dag = DAG(
dag_id='udf_example',
user_defined_macros={
"quick_format": quick_format,
}
)Now, the quick_format function can be used anywhere you would normally use a macro:
# Run SQL in BigQuery and export results to a table
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
run_sql = BigQueryOperator(
task_id='insert-into-table',
bigquery_conn_id='bigquery_default',
destination_dataset_table='project.dataset.table',
sql="SELECT * FROM table WHERE created_at_month = '{{ quick_format(ds,'%Y-%m') }}'",
dag=dag,
)This feature can help you build powerful, dynamic parameterization in your DAG. Perhaps you need to change the timezone of a date-based file path using the pendulum library. Perhaps your query needs a different WHERE clause every day of the week, and you don’t want to maintain seven SQL files. In either case, User-defined Macros provide an elegant solution.
XCom
What is it?
When chaining ETL tasks together in Airflow, you may want to use the output of one task as input to another task. Newcomers to Airflow understandably get frustrated the first time they realize they can’t do this using Python objects in the DAG file. However, Airflow does have this functionality.
Users can push and pull key-value pairs using XCom (short for Cross-Communication). The data is persisted in a table in Airflow’s backend database, so it’s accessible across DAGs and execution dates. This feature is very flexible and can be used in creative ways. Here’s an example of a company using XCom to reduce noise to their SFTP servers.
Coding Example
The following code shows how to retrieve a watermark using a PythonOperator, then use that watermark to parameterize a query:
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
# Instantiate your DAG
dag = DAG('xcom_example')
def retrieve_watermark(**kwargs):
# Retrieve watermark using Python
watermark_value = '2020-08-01'
# Push value to XCom. 'ti' stands for 'task instance'
kwargs['ti'].xcom_push(key='watermark', value=watermark_value)
return
with dag:
# Run above function
retrieveWatermark = PythonOperator(
task_id='retrieve_watermark',
# provide context for XCom
provide_context=True,
python_callable=retrieve_watermark,
)
# Run query using the XCom value
runSQL = BigQueryOperator(
task_id='insert-into-table',
destination_dataset_table='project.dataset.table',
sql="SELECT * FROM source WHERE created_at > '{{ task_instance.xcom_pull(task_ids='retrieveWatermark', key='watermark') }}'”
)
retrieveWatermark >> runSQLPossible Complications
XCom is possibly one of Airflow’s most powerful but least obvious features. However, it is also a major source of problems. You can technically store a dataset in XCom and pass it between tasks. However, this is highly inadvisable, as the data is persisted in Airflow’s backend database. But even when simply passing a date between tasks, it’s important to remember that XCom is not part of Airflow’s task dependency paradigm, and would be difficult to debug in a complex DAG. Other tools like Dagster do a much better job of including inputs and outputs in op graphs.
Task Sensor
What is it?
Within a DAG, you can generate a Task Dependency Graph by setting tasks upstream or downstream from each other. For example:
# The following three lines are equivalent
task_2.set_upstream(task_1)
task_1.set_downstream(task_2)
task_1 >> task_2This ensures that tasks run in the correct order and that downstream tasks don’t run if upstream tasks fail. However, we want to be able to do this within DAGs and across DAGs. This is where the External Task Sensor becomes useful.
Coding Example
Below is a simple DAG (dag_a) that generates a simple table (table_a) using SQL:
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
dag = DAG('dag_a')
target_table = 'table_a'
with dag:
run_sql = BigQueryOperator(
task_id=f'insert-into-{target_table}',
destination_dataset_table=f'project.dataset.{target_table}',
sql="SELECT * FROM `project.dataset.table`",
)There is another simple DAG (dag_b) that creates another simple table (table_b) by querying table_a. To ensure table_b waits until table_a is finished, the ExternalTaskSensor is used:
from airflow import DAG
from airflow.sensors.external_task_sensor import ExternalTaskSensor
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
dag = DAG('dag_b')
source_table = 'table_a'
target_table = 'table_b'
with dag:
check_external_task = ExternalTaskSensor(
task_id=f'check-{source_table}'
external_dag_id='dag_a',
external_task_id='insert-into-{source_table}',
)
run_sql = BigQueryOperator(
task_id=f'insert-into-{target_table}',
destination_dataset_table=f'project.dataset.{target_table}',
sql=f"SELECT * FROM `project.dataset.{source_table}`",
)
check_external_task >> run_sqlExtending the External Task Sensor
The External Task Sensor is an obvious win from a data integrity perspective. Even better, the Task Dependency Graph can be extended to downstream dependencies outside of Airflow! Airflow provides an experimental REST API, which other applications can use to check the status of tasks. You could use this to ensure your Dashboards and Reports wait to run until the tables they query are ready.
However, what if the upstream dependency is outside of Airflow? For example, perhaps your company has a legacy service for replicating tables from microservices into a central analytics database, and you don’t plan on migrating it to Airflow. While external services can GET Task Instances from Airflow, they unfortunately can’t POST them. Tasks with dependencies on this legacy replication service couldn’t use Task Sensors to check if their data is ready.
It would be great to see Airflow or Apache separate Airflow-esque task dependency into its own microservice, as it could be expanded to provide dependency management across all of your systems, not just Airflow. For example:
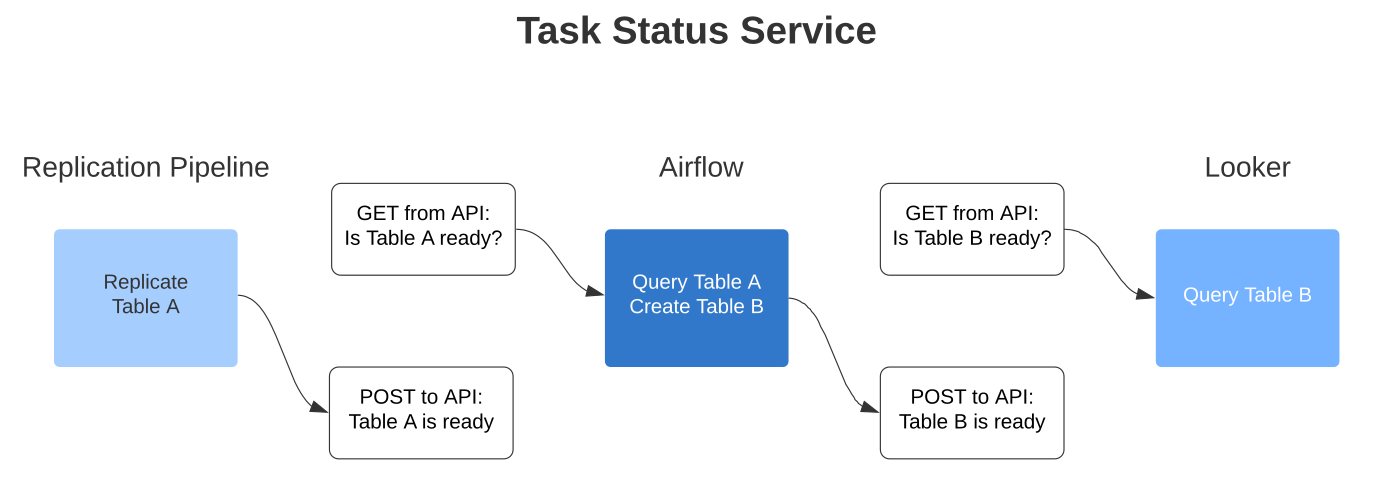
If this service had an API that supported GET and POST operations, you could easily write your own Sensors and Post Operators by extending the SimpleHTTPOperator, and use them instead of the ExternalTaskSensor.



