

The 3-in-1 toolkit for faster data migrations
Plan, translate, and validate data across systems seamlessly to massively accelerate your data migration project with new Datafold Cloud features.


One of my first large data migrations was at Lyft, where we migrated a petabyte-scale data warehouse from Redshift to a Hive/Spark/Trino-powered data lake. At almost every step of the migration, we encountered considerable roadblocks: understanding what to actually migrate (from hundreds of tables and 13k+ BI reports), converting SQL scripts of sometimes 1k+ lines of code to the new SQL dialect, and validating the migration to secure stakeholder sign-off.
What was supposed to be a one year process took more than three.
I know my experience at Lyft was not a unique one—data migration projects are long, expensive, manual, and they forfeit your team’s ability to undergo new and exciting analytics work. But they’re a natural progression as your organization, data, and team scale and mature (and technology improves in parallel).
So today, we announce the most exciting updates this year to the Datafold product to continue empower data teams to strike the balance between quality and velocity—but during a data migration.
Datafold Cloud now supports a 3-in-1 product experience to enable data teams to automate away the most tedious parts of a migration:
- Cross-Database Diffing: Run data diffs across SQL databases to validate the parity of data fast (seconds/minutes), at any scale.
- Column-Level Lineage: Identify dependencies and usage for each data asset to prioritize or deprecate data for migration in the most optimal way.
- SQL Translation: Translate your SQL queries with the click of a button. Spend 0 time on rewriting SQL and looking up SQL dialect nuances. When you use Datafold to help accelerate your data migration, you commit to higher data quality, work with greater speed and transparency, and remove the technical complexities of the most arduous parts of a migration.
Cross-database diffing: Automating away your validation with unparalleled performance
We took a poll on LinkedIn recently and asked people what the most tedious part of a data migration was; the answer was resounding (and my experience bias from Lyft confirmed): validating the legacy data versus the new data.
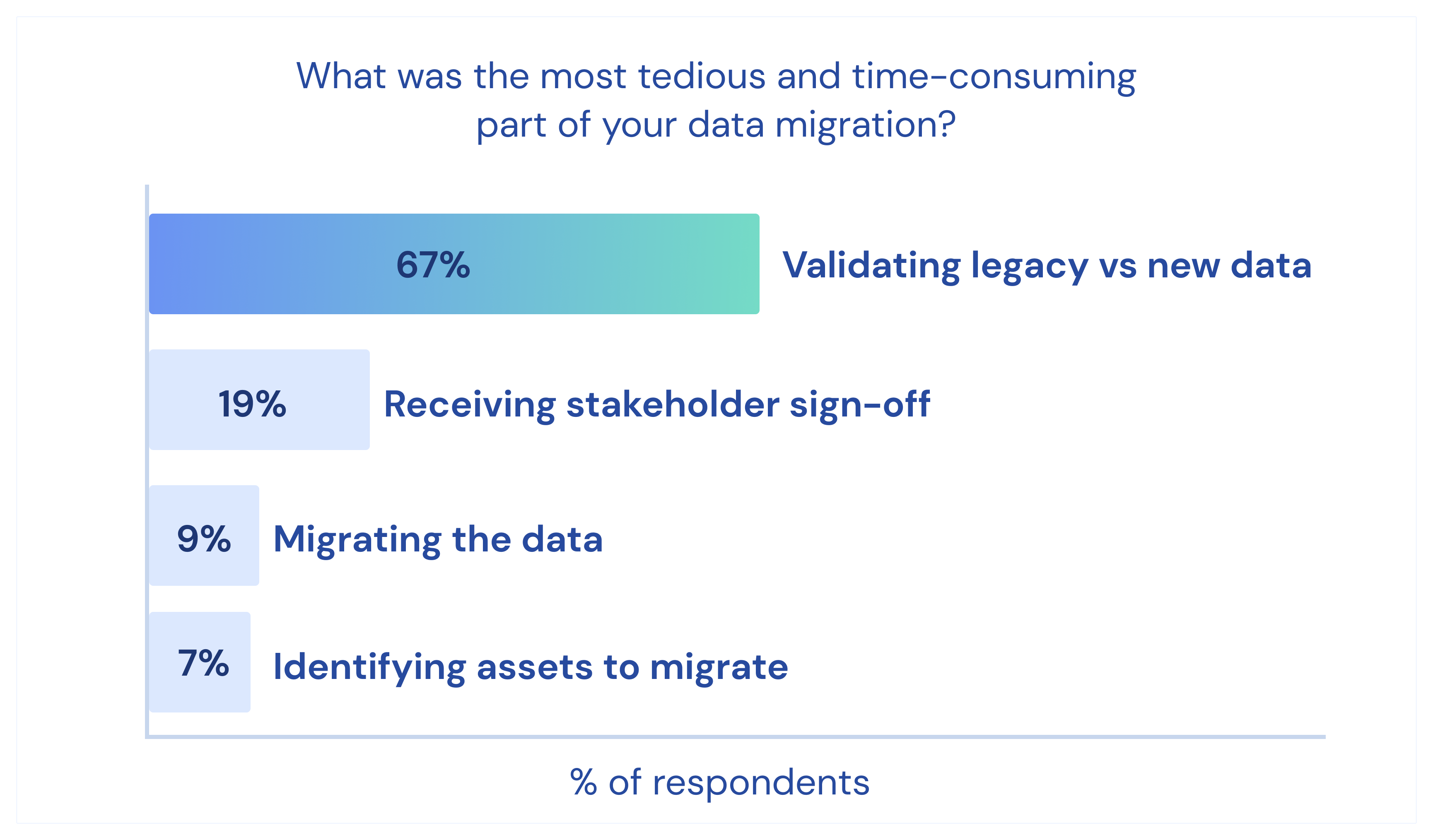 We know what the process typically looks like: jumping between databases, copying and running spot check SQL queries, and a lot of eyeballing the data. Not only is the process time-consuming and manual, but it does not guarantee parity between systems—the ultimate signal of a successful migration—or scale with your data. My biggest challenge running the migration at Lyft was that stakeholders refused to move off of the legacy system because we could not prove parity between that and the new one, massively slowing down our migration.
We know what the process typically looks like: jumping between databases, copying and running spot check SQL queries, and a lot of eyeballing the data. Not only is the process time-consuming and manual, but it does not guarantee parity between systems—the ultimate signal of a successful migration—or scale with your data. My biggest challenge running the migration at Lyft was that stakeholders refused to move off of the legacy system because we could not prove parity between that and the new one, massively slowing down our migration.
Datafold’s cross-database diffing is changing the migration validation process, so your team can work with greater speed and confidence. So your stakeholders actually trust you when you say, “The data is unchanged between our legacy and new database.”
With Datafold Cloud’s cross-database diffing, you can diff tables across databases in minutes. Automatically know if parity exists between systems, and if it doesn’t, explore the value-level differences within the Datafold UI.

Not only is Datafold’s data diffing removing the need for complex manual cross-database diffing, it’s doing them efficiently at scale. Below, we demonstrate the speed of Datafold Cloud’s cross-database diffing across SQL Server and Snowflake in different testing scenarios with varied row counts.
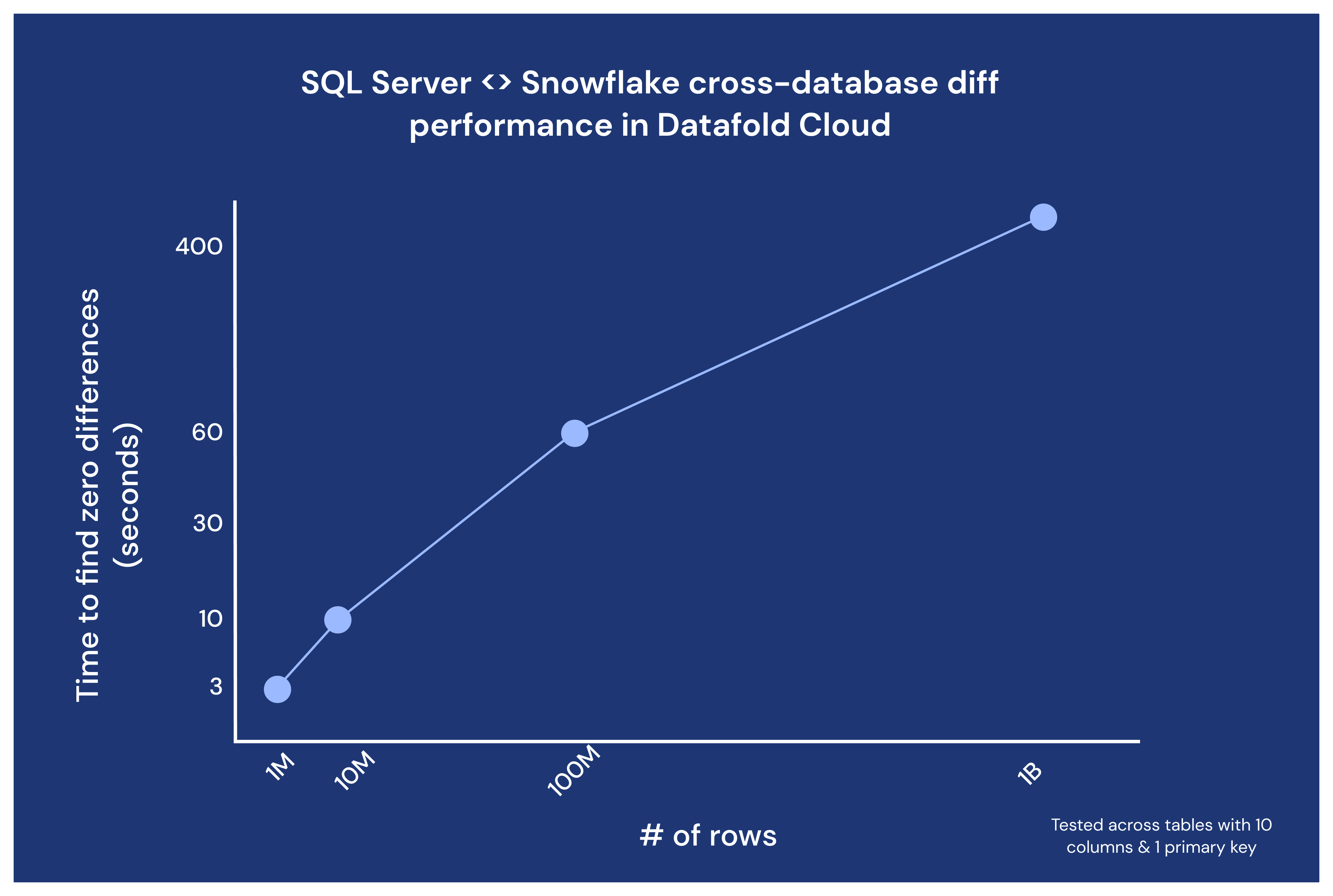
Datafold also supports the ability to run cross-database diffs within the Datafold Cloud UI and REST API, so your team can run diffs at scale and with automation by your side. Datafold Cloud’s cross-database diffing is compatible with 10+ SQL databases like Oracle, SQL Server, Teradata, Snowflake, Databricks, BigQuery, Redshift and more.
Ultimately, when you validate your migration with Datafold’s data diffing abilities, you enable your team to work with speed and help ensure stakeholder sign-off (and trust).
*“No question. I would recommend Datafold for any large scale migration.” *- Jon Medwig, Staff Data Engineer at Faire
Automating every step of the migration process
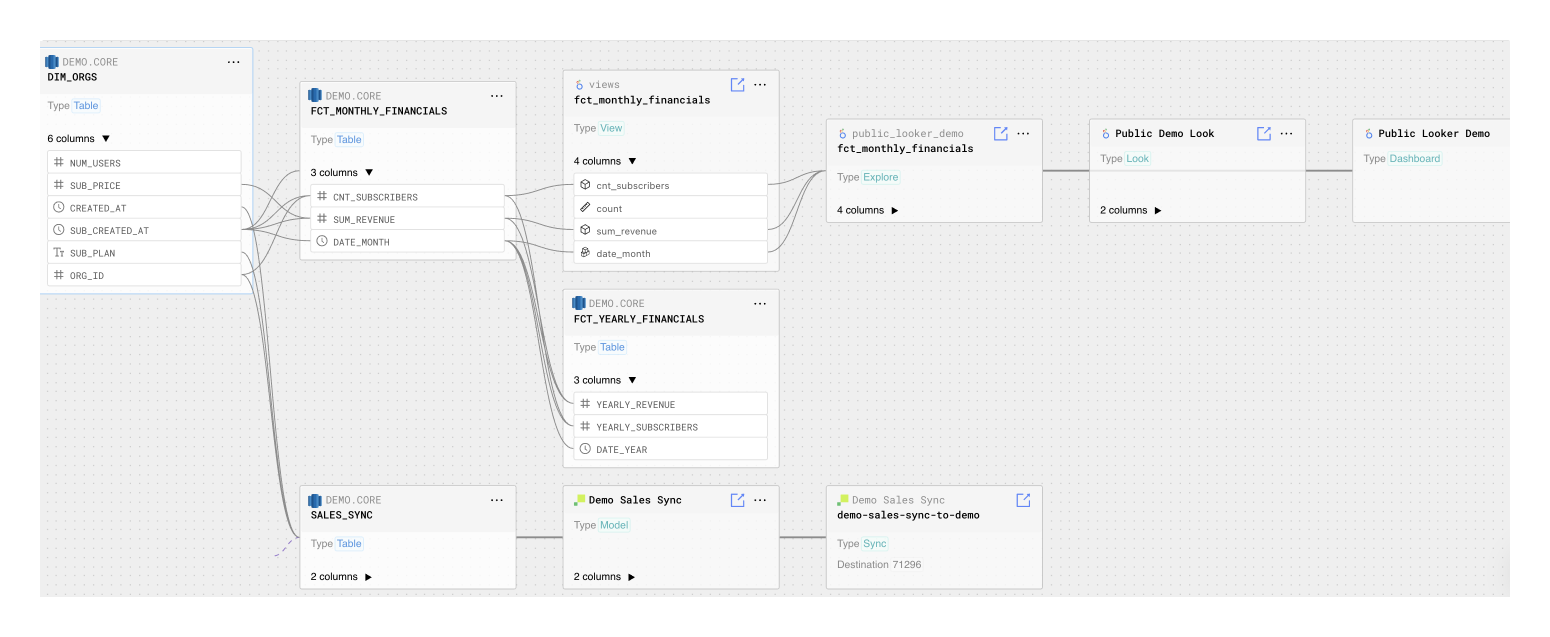
Prioritize and plan your migration smarter with column-level lineage
If you have thousands, or even hundreds, of SQL scripts and tables to migrate over—how do you start identifying and prioritizing them?
With column-level linage, quickly identify the assets that can be deprecated, prioritize the most important assets to migrate, and establish an order of operations for data dependences. Because Datafold’s column-level lineage is not limited to only your data warehouse and instead integrates with several BI tools like Tableau and Looker, your team can more easily understand how your data moves its way from source data to the most important dashboards in your BI tools.
The Google Translate of SQL
One of the most tedious (and just down-right annoying) parts of a migration is translating over your legacy database SQL to your new database’s SQL syntax.
Built on top of the SQLGlot package, Datafold Cloud’s SQL Translator allows you to input your legacy transformation code, select the original SQL dialect and the new SQL flavor you want, and automatically receive the new version of your original code within a simple UI. Say goodbye to those endless “X syntax in Snowflake” Google searches.
![]()
📽️ Demo
Watch Datafold Solutions Engineer Leo Folsom demo a cross-database diff between PostgreSQL and Snowflake for tables with over a million rows.
Change the way you migrate your data
If you’re ready to learn more about how Datafold is accelerating data teams to work during a migration, there’s a few options to getting started:
- Request a personalized demo with our team of data engineering experts. Tell us about your migration, tech stack, scale, and concerns. We’re here to help you understand if data diffing is a solution to your migration concerns.
- Join us at our next live Datafold Cloud Demo Day on December 7th—this is a great way to see the product live and ask our team of solution engineers any questions you might have about the product experience.
- For those who are ready to start playing with cross-database diffing today, we have a free trial experience of Datafold Cloud, so you can start connecting your databases as soon as today. As we said in the beginning of this blog: migrations are hard, potentially years-long projects. Datafold is here to make them as automated as possible, so your team can focus on what matters: providing high quality data to your organization.
Happy diffing!



