

The Lowdown: Open source data-diff vs. Datafold Cloud
Learn about how open source data-diff and Datafold Cloud differ 😉 and determine which one meets your data quality testing needs.


At Datafold, we believe every data practitioner should be data diffing; we also understand that all practitioners have different team set-ups, financial constraints, and data stacks that make adopting new tooling or methods to be difficult (or even impossible). This is one of the reasons Datafold supports both an open source (data-diff) and SaaS version (Datafold Cloud) to enable seamless (and accessible) data diffing.
In this article, we’ll cover in detail how these two solutions differ and unpack which one might be most appropriate for you. Specifically, we’ll discuss:
- What is open source data-diff?
- What is Datafold Cloud?
- Differences and similarities between the two
- Choosing the right option for you
💡 What is a data diff? In the simplest of terms,** data diffing is the act of comparing two tables to check whether every value has changed, stayed the same, been added, or removed between the two tables.** To compare it to something familiar, you can think of a data diff as a git code diff, but for the tables in your data warehouse.
What is open source data-diff?
Open source data-diff is an open source Python package that allows you to perform data diffs across two tables in their database(s). Running a data diff using the open source data-diff package will return a high-level overview of differences between two tables. A sample data-diff output would look like this:
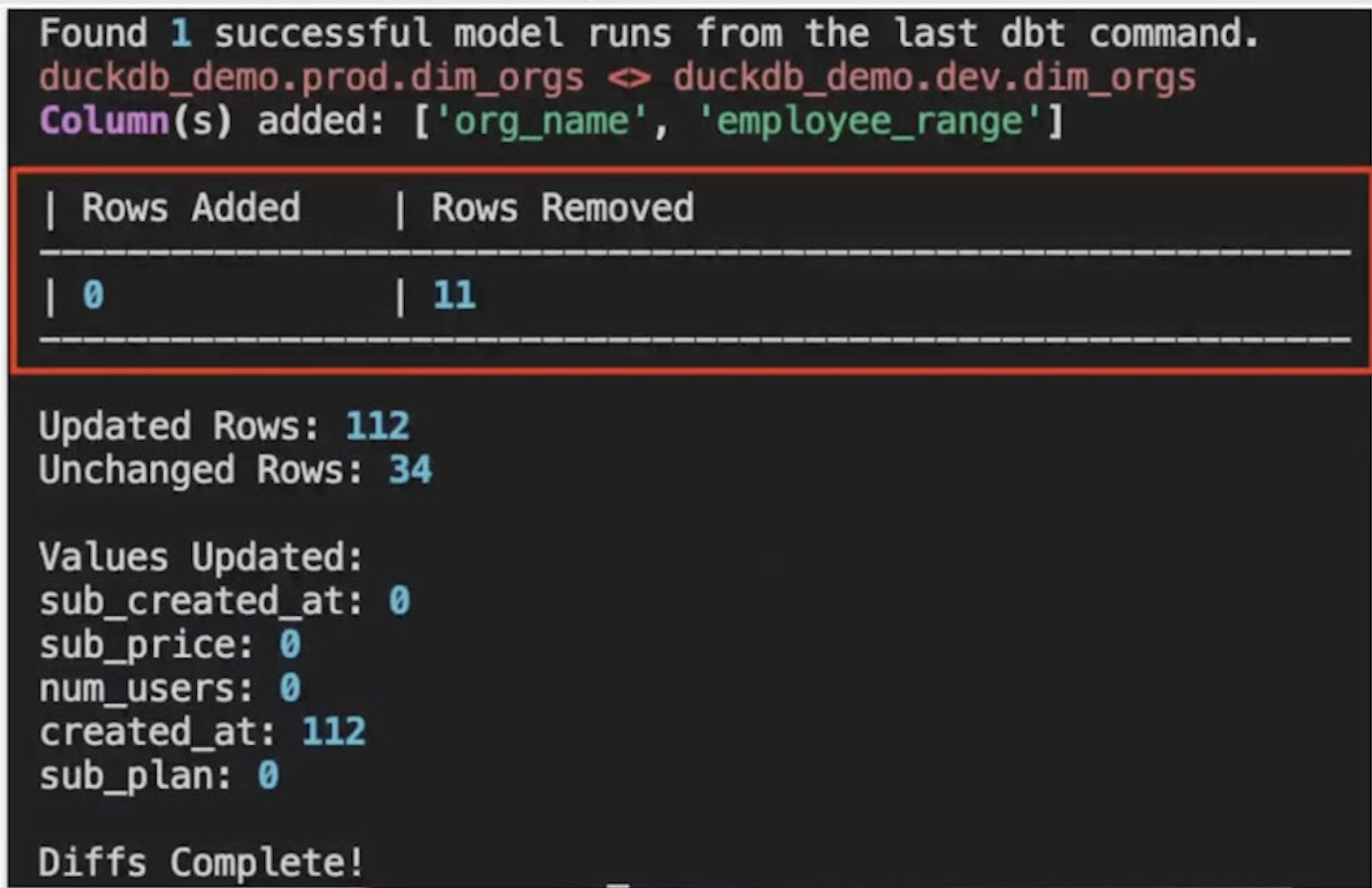 At a high-level, you can use open source data-diff to understand:
At a high-level, you can use open source data-diff to understand:
- How many rows were added or removed between the two tables
- If any column-values changed between two tables
- If there were any schema changes (columns added or removed) To use open source data-diff, you can simply pip install the data-diff package and start creating diffs between two tables using the command line interface (CLI).
Open source data-diff is a useful package for:
- Ad hoc data diffs during development: Quickly compare two tables in your data warehouse(s) to understand how they may differ. Particularly useful for dbt developers who want to compare production and development versions of specific models ad hoc.
- Data migrations and replication: For teams undergoing database migrations or replication, use data-diff to ensure parity and perform cross-data warehouse comparisons on tables in different warehouses.
- Single developers: For individual developers who need to quickly perform data diffs without needing to automate diffs or democratize diff results, open source data-diff is a strong option for them.
How does open source data-diff work with dbt?
In case you missed it, we’re pretty big fans of dbt 😉. Using open source data-diff’s dbt integration or the Datafold VS Code Extension, you can quickly diff between dbt models to speed up your dbt development.
By simply running (from the CLI or the VS Code Extension):
dbt run --select && data-diff --dbt
you can diff the prod and dev versions of that specific dbt model. Using this integration, you automatically understand exactly how your dbt models differ between your prod and dev versions and how your code changes will change the underlying data, ultimately allowing you to develop with greater speed and confidence.

What is Datafold Cloud?
Datafold Cloud is the data diffing solution for teams. At a high-level, Datafold Cloud supports:
- Running data diffs ad hoc, during dbt development, and automatically with CI
- Column-level lineage for robust dependency analysis within and outside of your dbt project
- A secure and compliant hosted SaaS app or single-tenant solution Let’s dive into these a bit!
Varied data diffing capabilities
Using Datafold Cloud, you can perform data diffs ad hoc, during your dbt development, or automatically in CI for confident deployments. A general workflow using Datafold Cloud would look like:
- Development testing: Make dbt model changes and diff the prod and dev versions of changed models using the Datafold Cloud CLI integration or the Datafold VS Code Extension.
- Deployment testing: Once you feel good about your code changes, open up your PR and automatically perform data diffs during CI. Data diff results will automatically be added as a PR comment, so you, your team, and your PR reviewer understand deeply how code changes will potentially impact production data and downstream dbt models, BI tools, or data apps.
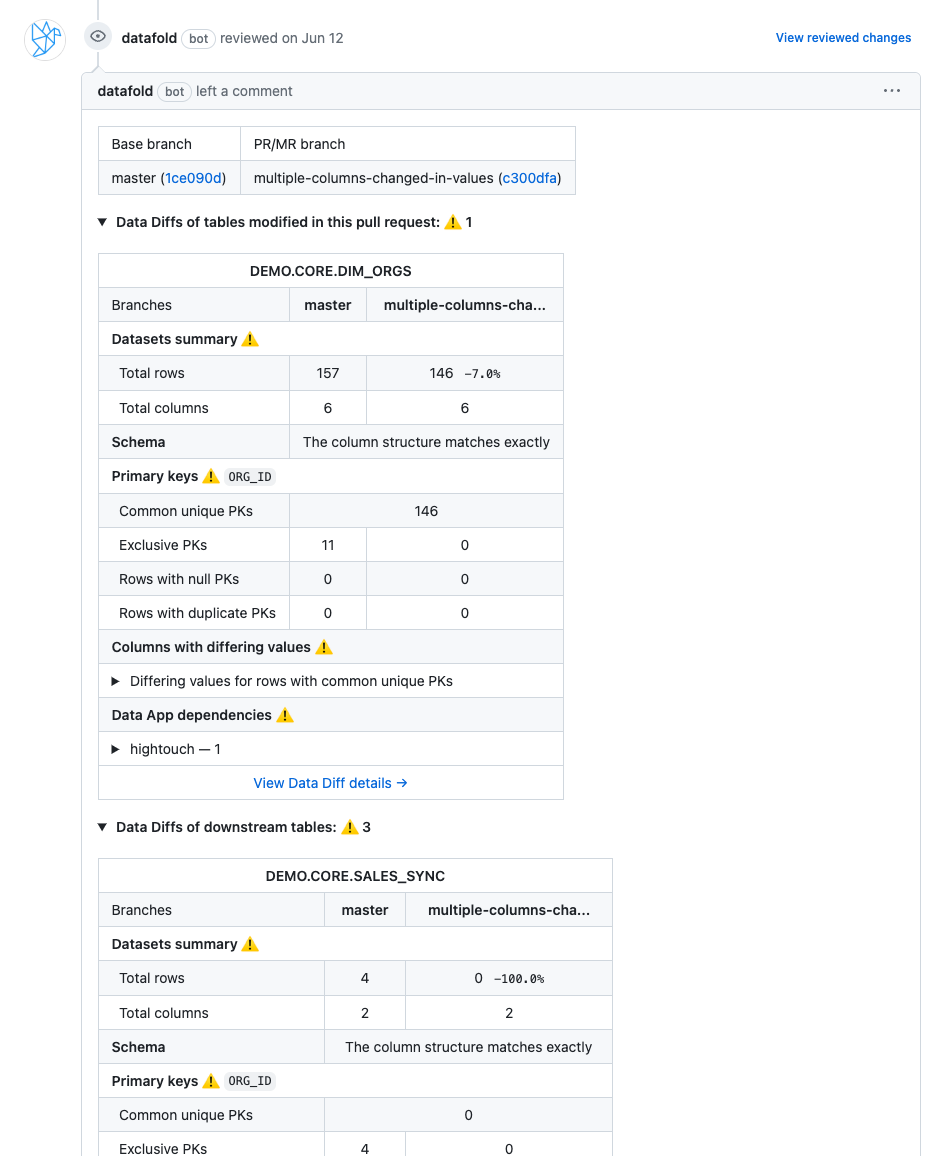 By integrating data diffing during deployment and CI, your code changes must go through automated data diffs. You, your team, and potentially impacted stakeholders get clear visibility into how the data will change, determine as a team if these changes are acceptable (or unexpected), and govern your data quality with automation, thoroughness, and speed by your side.
By integrating data diffing during deployment and CI, your code changes must go through automated data diffs. You, your team, and potentially impacted stakeholders get clear visibility into how the data will change, determine as a team if these changes are acceptable (or unexpected), and govern your data quality with automation, thoroughness, and speed by your side.
Unlike open source data-diff, Datafold Cloud also allows you to have a thorough understanding of diff results by enabling visual **value-level diffs **in both the Datafold Cloud application as well as right within your VS Code workflow. With Datafold Cloud, you can not only receive high-level overview of diffs, but you can view row-by-row, value-by-value data diffs to see how values level may differ between two tables:
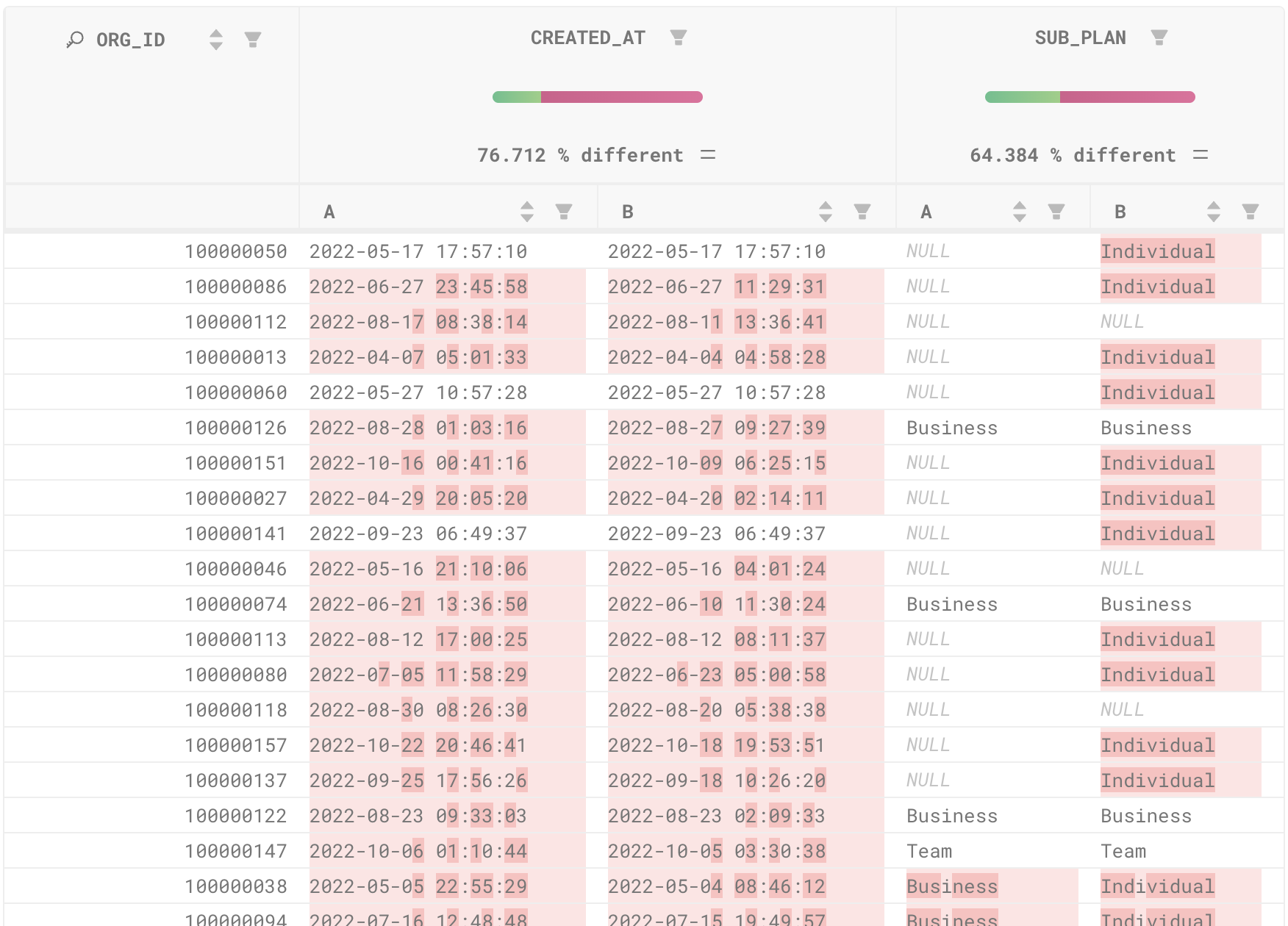 With this level of granularity, you can look at specific rows that shouldn’t have (or should have) changed due to your code updates, better understand if your code changes are handling edge cases, and give you complete control over your data quality.
With this level of granularity, you can look at specific rows that shouldn’t have (or should have) changed due to your code updates, better understand if your code changes are handling edge cases, and give you complete control over your data quality.
For teams that need to run a large number of diffs at scale (say for automating diffs during a database migration), Datafold Cloud users also have access to the Datafold REST API to trigger hundreds or thousands of diffs with a few lines of code.
Column-level lineage
One of the key differentiators between Datafold Cloud and open source data-diff is Datafold Cloud’s expansive column-level lineage. Using column-level lineage, teams can easily trace dependencies across your dbt project, BI tools, and data apps, giving you a fine-grained view into your data’s ecosystem.
Because Datafold Cloud’s column-level lineage leverages a proprietary multi-dialect SQL compiler to analyze your data warehouses’s query logs (as opposed to parsing your dbt project’s manifest.json) for creating column-level lineage, it allows Datafold to find dependencies that go beyond your dbt project (including those surprise ad hoc tables built on top of dbt) and can work through the messiest SQL statements with CTEs and subqueries. These downstream dependencies could include BI tools like Mode, Looker, and Tableau, and data apps like Hightouch syncs.
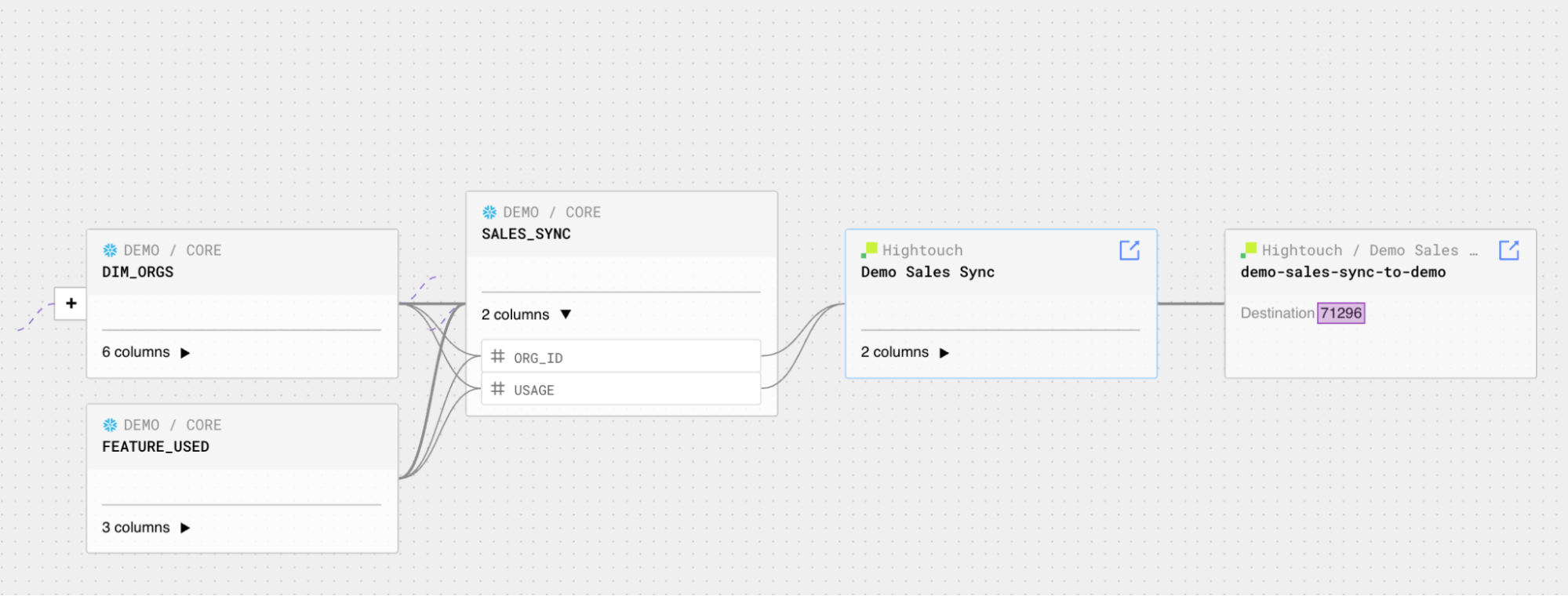 Using this information, Datafold Cloud’s PR comment provides visibility into potentially impacted data apps and BI tools from proposed dbt code changes, so both you, your team, and end users understand potential impact before deployment.
Using this information, Datafold Cloud’s PR comment provides visibility into potentially impacted data apps and BI tools from proposed dbt code changes, so both you, your team, and end users understand potential impact before deployment.
Hosted and secure solution
Datafold Cloud enables your team to diff in a secure and compliant environment. Datafold Cloud’s SaaS application is SOC 2 Type II, HIPAA, and GDPR compliant, so you can perform data quality tests with confidence. In addition, for teams that need an uber-secure environment to diff and share diff results, Datafold also supports single-tenant solutions.
Comparing open source data-diff and Datafold Cloud
Below is a high-level overview of how open source data-diff and Datafold Cloud differ from a use case, tech stack, and feature set.
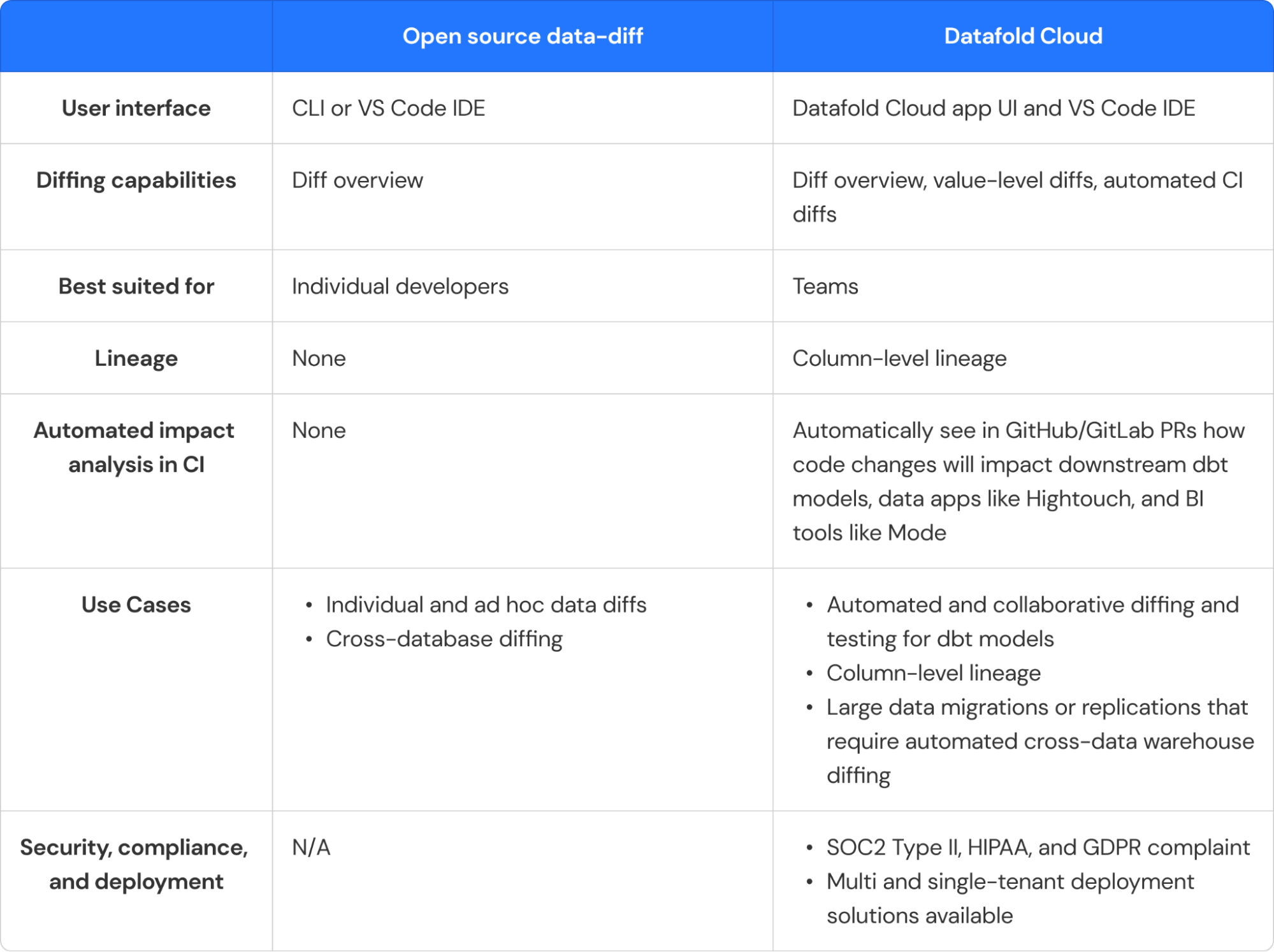
Want to learn more about how open source data-diff and Datafold Cloud differ? Reach out to our team to get the nitty-gritty details on the two.
How do I know which one’s right for me?
So, what’s the best data diffing solution for you? Like we said earlier, we believe all data practitioners should be not only testing their data, but performing data diffs to find data quality issues before they enter your production pipelines. Whether open source data-diff is a great place for you to start, or you’re ready for your team to jump in and adopt Datafold Cloud, we’re here to help.
Some additional considerations to think about when deciding which data diffing solution is best for you:
-
Is your team going to be growing in the near future?
-
How complex is your data or dbt project right now? Will that be changing in the future?
-
Does your team require automated tests? Or is ad hoc enough?
-
Are compliance and security mandatory requirements, or more like nice-to-haves?
-
Does your team need column-level lineage to address impact and dependency analysis? If you’re ready to learn more or get started with diffing, check out the following resources:
-
For individual developers, check out the Datafold VS Code Extension or open source data-diff installation guides
-
For teams who want to see Datafold Cloud in action, see a live demo to learn more and get all your pressing questions answered Happy diffing!



