

Open source data-diff
Open source data-diff automates data quality checks for data replication and migration.

As of May 17, 2024, Datafold is no longer actively supporting or developing open source data-diff. For continued access to in-database and cross-database diffing, please check out our free trial of Datafold Cloud. We’re grateful to everyone who made contributions along the way. Please see our blog post for additional context on this decision.
Compare tables of any size across databases
We’re excited to announce the launch of a new open-source product – data-diff that makes comparing datasets across databases fast at any scale.
data-diff automates data quality checks for data replication and migration. In modern data platforms, data is constantly moving between systems, and at the modern data volume and complexity, systems go out of sync all the time. Until now, there has not been any tooling to ensure that when the data is correctly copied.
Why Replication Needs Validation
Replicating data at scale, across hundreds of tables, with low latency and at a reasonable infrastructure cost is a hard problem, and most data teams we’ve talked to, have faced data quality issues in their replication processes. The hard truth is that the quality of the replication is the quality of the data.
Since copying entire datasets in batch is often infeasible at modern data scale, businesses rely on Change Data Capture (CDC) approach of replicating data using a continuous stream of updates. In CDC pipelines, individual messages can be sometimes lost, and that can cause the source and target datasets to drift apart significantly.

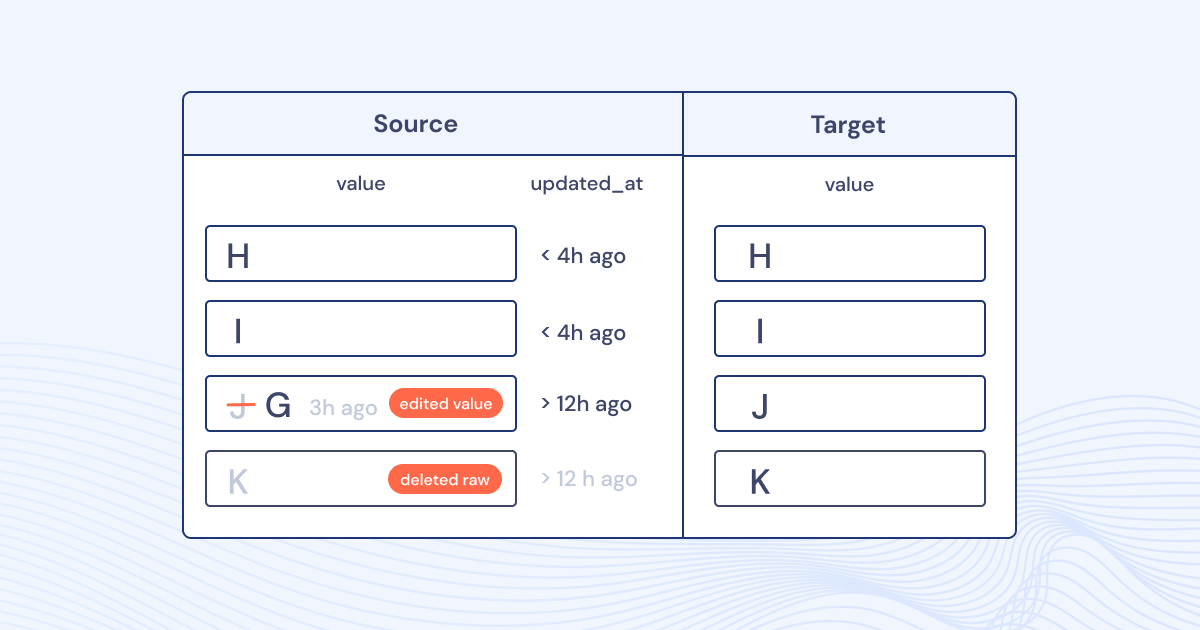
Besides message loss, common sources of inconsistencies are hard deletes – when a record is removed from the source database instead of being flagged as deleted (a soft delete) – and stale update timestamps: it is common to use “updated_at” field to mark the last time a given record was changed. If a record was changed without the update to the timestamp field (common mistake when doing database maintenance and schema migrations), it may not be picked up for replication to the target system.
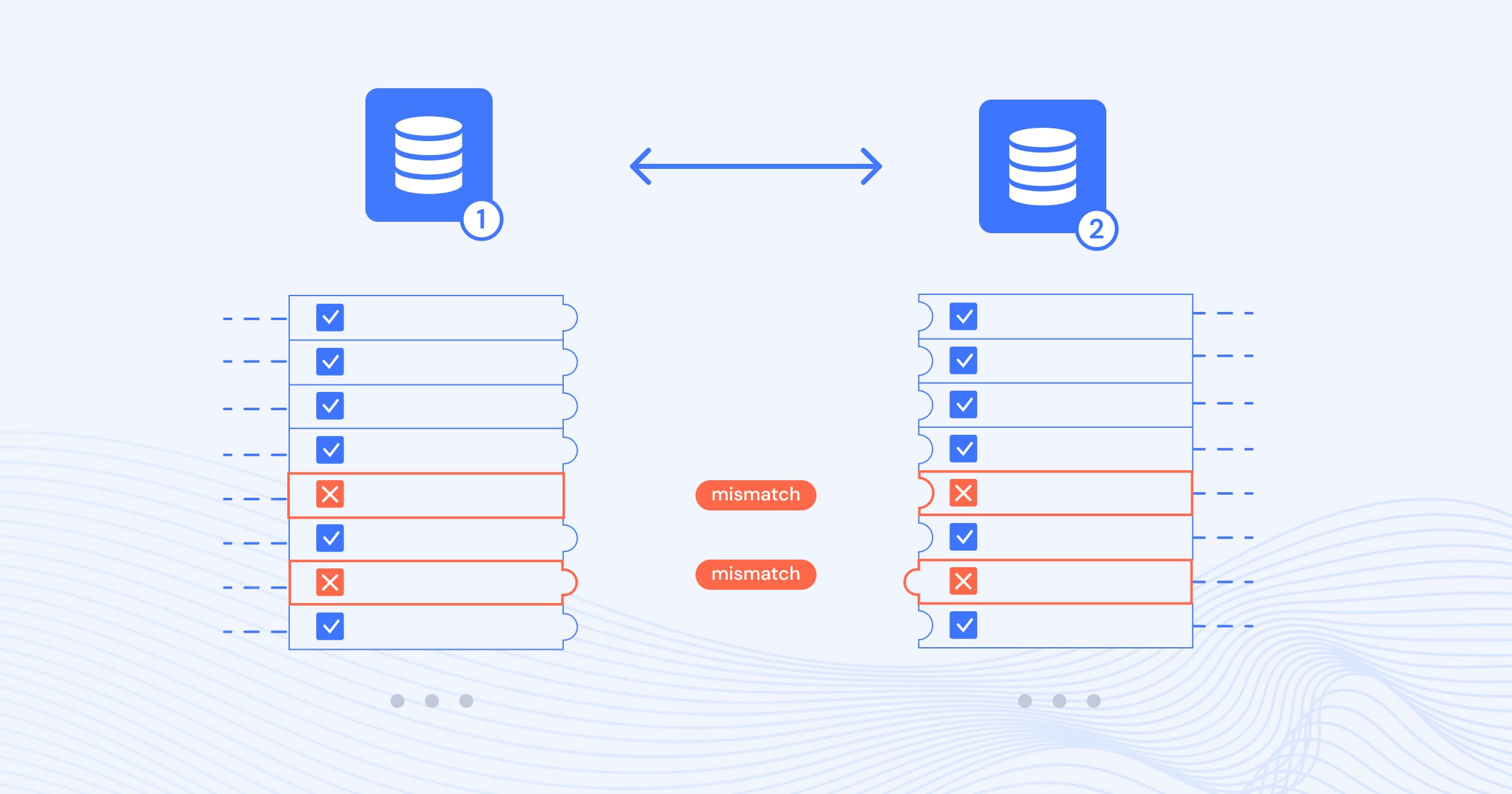
The biggest problem really is that most of these issues are happening silently – without an easy way to detect inconsistencies between source and target datasets, one can never be sure in the quality of the data moved across the network.
There has been no tooling for validating consistency of data across databases quickly and conveniently, and existing approaches were either crude (e.g. comparing row counts) or slow, expensive and non-scalable (e.g. pulling every record in and comparing it).
How to Find Mismatches Across Databases
We can map the existing solutions on the speed at which it can find mismatches and to what level of detail it can find about mismatches (there are differences vs here are the exact rows/values that don’t match).

- Compare row counts:
-
Fast
-
Gives quick answer if there are big mismatches (e.g. missing rows)
- Does not detect inconsistencies WITHIN records. E.g. we have same number of rows, but the data in certain fields is stale.
- Hash both tables (e.g. MD5) and compare hashes
-
Fast
-
Tells if the data including all contents is the same (more accurate than COUNT)
-
Does not tell the SCALE of the difference. (1 value / 1 row or 50% of rows affected?) – a single different value in a 1B rows x 300 column table will result in a different hash, same result as if the tables were entirely different.
-
Does not tell which values / rows are different
-
Differences in database type implementation and hashing make comparisons very complex
- Compare all records from source and target systems
- Very slow or very expensive (requires sending data across the network and computing everything)
- Gives detailed analysis of the difference
- Open source data-diff
-
Asymptotically (same order of magnitude) as fast as count
-
As detailed and accurate as “compare every row option”
-
Handles all cross-database type compatibility complexity
-
You can choose how much performance versus correctness you want. Validate fewer columns, and it’s faster. Validate more columns, and it’s safer, but slower.
- If there are lots of changes, it’s slower than comparing every row, especially for smaller tables.
How data-diff works
Data-diff provides superior speed and accuracy by using an algorithm that resembles binary search on hashes: it divides the dataset into chunks and compares the hashes of each chunk. If chunks don’t match, it further divides the chunk into smaller pieces and compares hashes of those until it finds diverging records. This algorithm only requires that a few hash values are transferred over the network as opposed to actual data, making it extremely IO efficient. It also parallelizes well which allows to diff 1B rows across, for example, PostgreSQL and Snowflake on a laptop in less than 5 minutes.
Check out README for more detail.



