

Why Looker was and Lightdash is a big deal for BI
Lightdash is an open-source alternative to Looker that natively integrates with dbt. It may not be as mature as other open-source products like Metabase, Querybook, or Superset, but it is different in a few essential ways.


Lightdash is an open-source alternative to Looker that natively integrates with dbt. It may not be as mature as other open-source products like Metabase, Querybook, or Superset, but it is different in a few essential ways.
To explain why Lightdash matters, it’s helpful to contemplate what’s so special about Looker (besides it being acquired by Google for $2.6B) and how it managed to become the most data-quality-aware BI tool on the market.
BI & Data Quality
Too often, discussions about data quality are centered on issues in ETL pipelines: missing values, breaking changes, infra downtime, and so on. However, we can’t forget about the business intelligence (BI) layer that serves as the front end to data and, therefore, plays a huge role in ensuring that the data users are making their decisions by looking at the right data in the right way.
Most BI tools adopted a hands-off approach to data quality by expecting the users to bring the properly cleaned and modeled data into the tool, optimizing for seamless SQL-to-chart flow. However, in a modern context, this is too much of an ask from the users: data is massive, complex, and most data users don’t know enough about it to be able to write SQL themselves.
Some of the big whales of BI such as Tableau and PowerBI took a step further and allowed users to define relationships between datasets, dimensions, and metrics in the UI that added some guardrails. But the desktop origin of both products together with the UI-first approach made the overall experience clunky.
Looker took a different path by combining the analyst-centric no-code exploratory experience with an engineer-centric modeling layer expressed in version-controlled code, and by being 100% cloud-based. The resulting product has gained wide adoption and became a default BI tool in the modern data stack.
So what about data quality? Simply put, Looker makes it possible for a large number of data users in an organization to explore, analyze, and dashboard data without writing code, and, therefore, helps them avoid the pitfalls of bad or incorrectly used data. This is made possible by Looker’s modeling (or semantic) layer – LookML – that lets data developers in the organization tell the tool how data works and set guardrails for the end users.
This is how LookML looks:
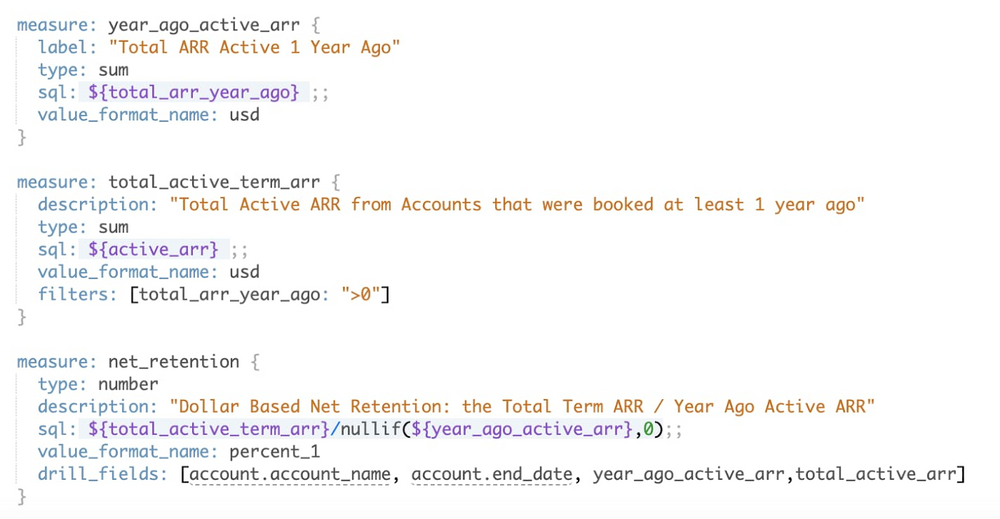
And this is what the end user sees. The definitions of measures (metrics), dimensions, and relationships get rendered in this drag-and-drop UI:

The benefits of a modeling layer in the BI tool
- Productivity: Who wants to type SQL every time to answer even the most basic questions? One of the benefits of having a data model defined in your BI tool is to unlock a truly self-serve, no-code data analysis.
- Data quality: The modeling layer brings structure, provides a single source of truth by keeping your business logic DRY, and facilitates reliable change management with version control. Need to add a new metric to cover a feature launch? Make a pull request to add some code!
- Scalability: By managing business logic in a structured way, the BI tool can scale to thousands of data users while providing transparent and effective access control, minimize load on the data warehouse with smart caching, and reduce the amount of duplicate content created and shared Despite these benefits, Looker has a few drawbacks:
- It’s a proprietary platform
- It’s owned by Google (which potentially may result in decreased interoperability with systems outside of GCP)
- It lacks integrations with other parts of the data stack, most importantly – the transformation layer which leads to a problem: where do you keep your business logic? These are the exact issues that Lightdash with its open-core approach and native integration with dbt aims to solve. While it’s still far away from being enterprise-ready, it’s closely aligned with the major trends of the modern data stack. So at the very least go star them on Github ✨🙂.



