

How to Trace PII with Column-level Lineage
There are plenty of rules around PII, but you can stay on top of where your sensitive data is flowing in your pipelines with column-level lineage.
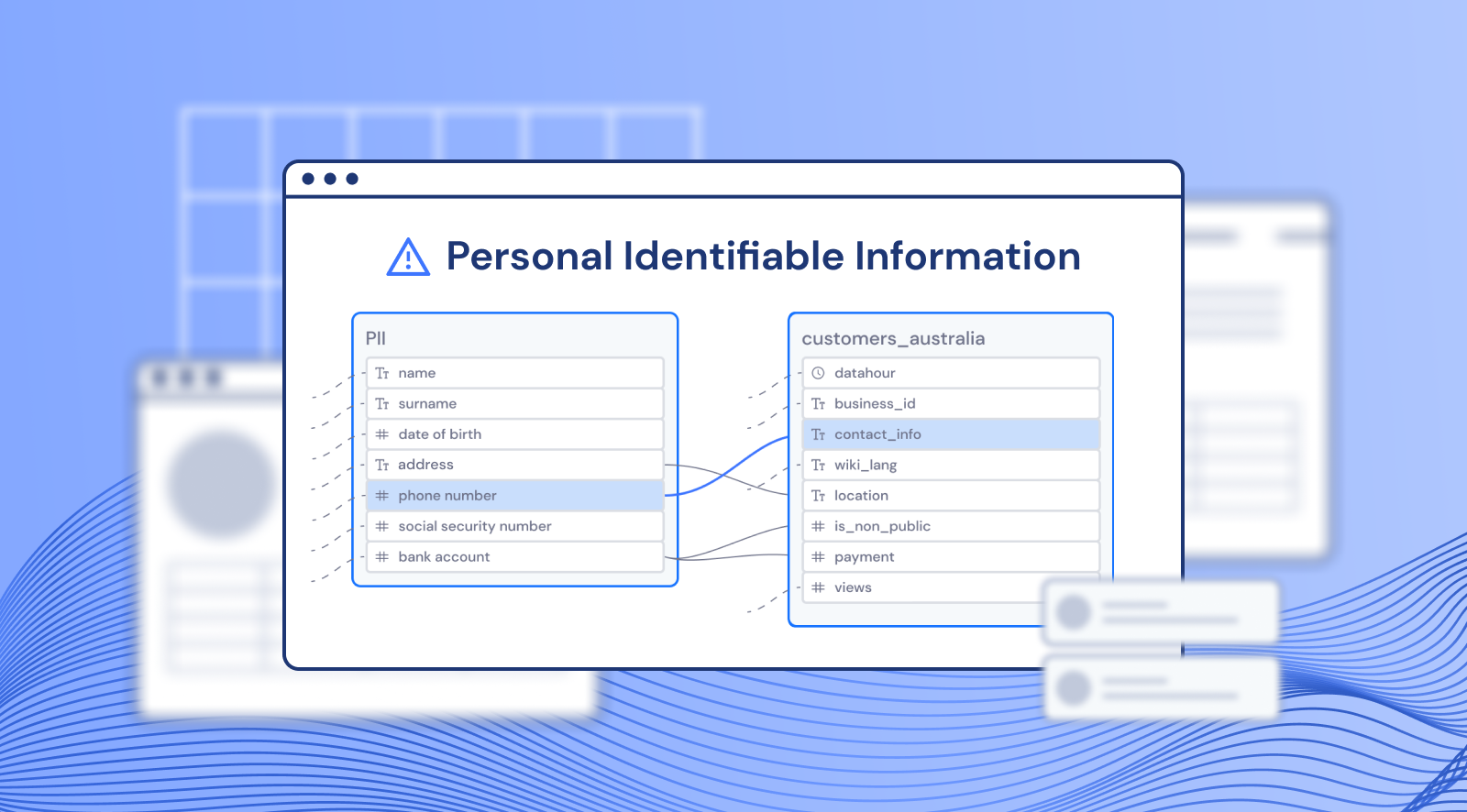
If terms like Personally Identifiable Information (PII), data consent, or GDPR are starting to pop up in your planning sessions, KPIs, or OKRs, it’s time to get a handle on how your sensitive data is flowing through your data pipelines. There can be a ton of rules and regulations around this, and the process can seem daunting at first. But the first step is always to identify and understand the situation so that you can start a journey towards greater compliance and consumer protection.
Before you can delete PII from a dashboard, report, or other data asset, you need to find it and figure out how it ended up in the final product. Column-level lineage makes it easy to trace your data through upstream and downstream processes. Datafold’s UI makes it simple to tag and track those sensitive fields so that you can discover all the potential implications of the PII in your data pipeline.
What is PII and How Can It End Up Where It Shouldn’t?
PII is any information that would allow an individual to be identified directly or indirectly. It can include full names, email addresses, phone numbers, social security numbers, bank account details, date of birth, or even user names or numbers. While users may give their consent for the collection of this information, they may not necessarily consent to how it is used or shared, expecting varying levels of privacy or security.
As explained by Katharine Jarmul, data engineers are primarily focused on getting data cleaned, tested, and validated as it moves through the data pipeline efficiently. However, sometimes in the process of optimizing these workflows, PII or other sensitive information can end up in places where it may or may not belong. For example, aggregate analytics might still include usernames if they weren’t dropped from the dataset, or chatbot training models might accidentally include email addresses if those aren’t cleaned.
Column-level Lineage for PII and Data Provenance Tracking
Whether you’ve been tasked with consent tracking or simply need to be able to say with confidence that your executive dashboards don’t contain any PII, data lineage is vital. Through data provenance tracking you can be clear about where the data is coming from, which elements are retained throughout the data pipeline, and where you need to be extra careful. This is where column-level lineage shines.
Datafold constructs an intuitive lineage graph by parsing every SQL statement that hits your data warehouse. This makes it easy to see how data is created and consumed, all the way down to the column level. For example, if you know that PII data first appears on a specific table, in a given column, you can select that field and choose to only show columns on its downstream path, making it easy to see where that information flows.

To make this even easier to track across teams and over time, Datafold allows you to tag columns. This means that once a data practitioner identifies the potential sources of PII and tags them as such, all other data team members can be aware of the PII in the pipeline and collaborate to ensure that it doesn’t end up moving through the data pipeline into data assets or reports.
 For optimal PII tracking, we support fetching the tags from dbt as part of our seamless integration. This can streamline your process and ensure that you catch all potential sources of sensitive information.
For optimal PII tracking, we support fetching the tags from dbt as part of our seamless integration. This can streamline your process and ensure that you catch all potential sources of sensitive information.
Datafold recommends PII tagging as a column-level lineage best practice. No one is perfect; people can also forget to set tags. Datafold supports manual curation of tags from Datafold’s own UI, but we also fetch tags from external sources such as dbt or Snowflake’s query tags. Our data sources become increasingly varied and can include information that has unintended identifiers. Finding and removing PII from core reports or executive dashboards often isn’t a one-off activity, but part of ongoing privacy and security efforts.
We know that many of you are grappling with enhanced compliance requirements or new privacy regulations in your field, or simply worry that you might be missing something when it comes to PII in your data pipeline. Let us show you how Datafold’s column-level lineage can help - feel free to explore our sandbox or contact us to see it in action.



