

Datafold for Everyone
Datafold has launched new pricing to make data quality more accessible for analytics engineers and data engineers.

At Datafold we believe that high productivity and quality of life for analytics engineers is as important as hiring great talent. After serving leading enterprise data teams at Patreon, Thumbtack, and others for the past few years, Datafold is now launching a free-tier and transparent cloud pricing.
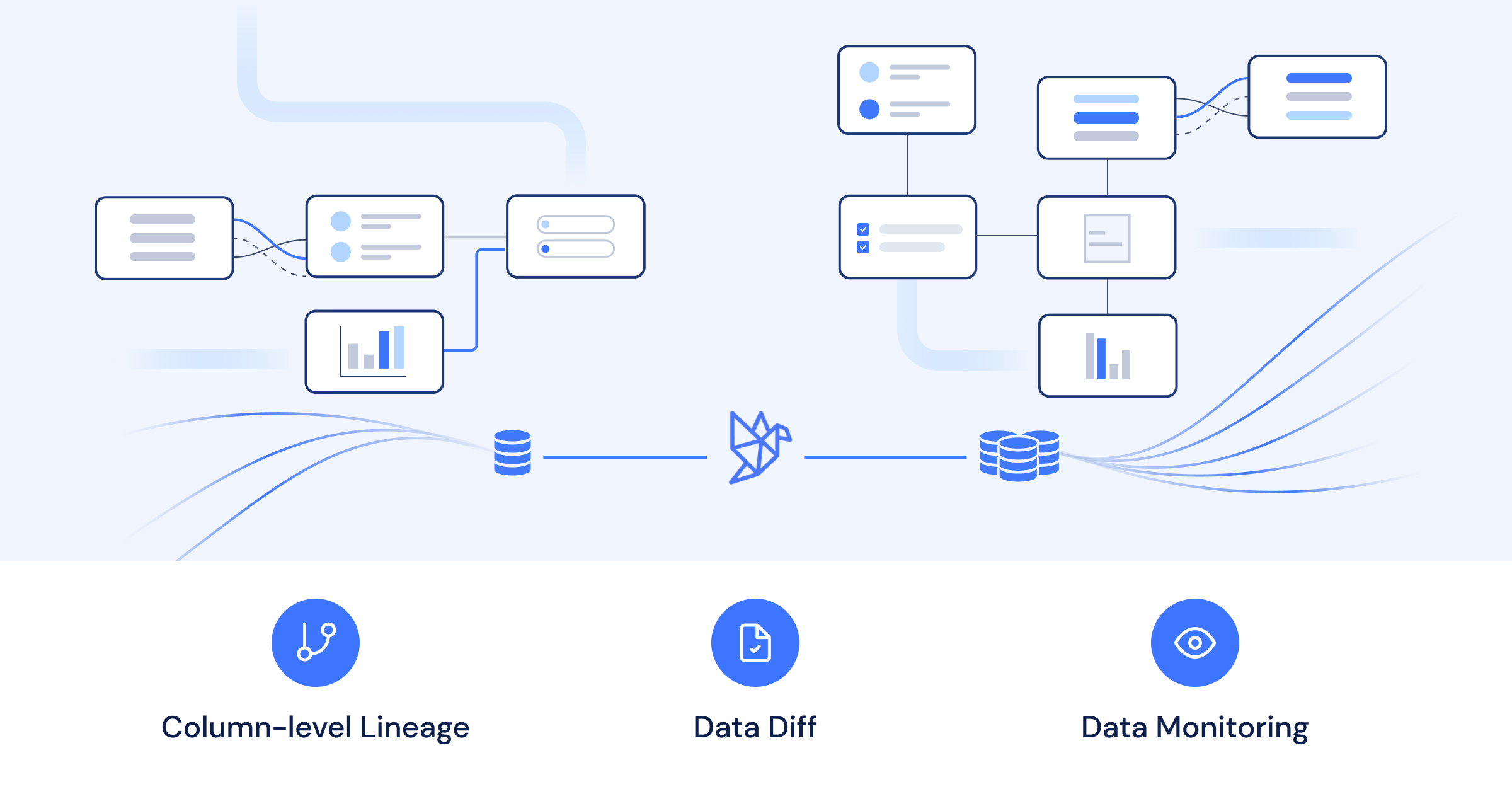
These new tiers enable any data team with essential developer tools such as Data Diff that automates testing of changes to data pipelines (dbt models) and column-level lineage which provides essential observability into data.
Developer tools for data in the past
Having practiced data engineering for six years at places ranging from archetypical Silicon Valley (I mean the show) startups to hyper-growth big-tech to public companies, I’ve always been amazed at:
- How much leverage data engineers have in the organization
- How little tooling support data engineers have – it always felt like we’re 10-15 years behind software engineers Tooling has been brutally bad. Pretty much everything in data engineering has been revolving around Airflow for the last 5-7 years. Building with Airflow has been like working in an early power plant – it’s powerful but sometimes the machine eats your fingers or blows up the entire plant. It does the job well and the concepts are simple but boy has anyone thought about the developer experience?
The big leap with dbt
dbt went so viral not because it was a marvelous invention but because it packaged the same concepts (sequential data transformations) in a developer-friendly way, making adhering to reasonable time-proven best practices such as version control, separating development from production, and testing easy to implement.
Everyone agrees that dbt improved the lives of data engineers dramatically.
At the same time, there is a strong demand for further improvement of developer experience and “quality of life”. Some of those demands manifest themselves in concrete asks such as improved CLI interface, modern IDE features such as autocomplete, etc.
Developer tools for data in the future
The biggest apparent gap in the data/analytics engineering workflow is that the practitioners execute blindly. We don’t know enough about what data is at our disposal, what’s been done already and what is the right data to use in their work and how to use it correctly, leading to duplication of work, misuse of data and slow progress.
The solution to that is leveraging metadata and lineage to provide you with a clear picture of what’s going on in your data warehouse within your current workflow. Whether this is available in a single tool or not, the essential components are:
-
**Column-level lineage **– understanding how is data computed and from what sources and how it is consumed. Having this information readily available enables any data practitioner to reason about the substance, importance and reliability of any given data. Ideally, through an intuitive UI. Add API to that and you can also automate lots of data ops tasks.
-
**Data diffing **– being able to compare staging to production of your data models to see how the underlying data changes before you merge. Having this information allows data engineers to make informed choices about the model updates they make instead of getting surprised by a stakeholder alerting them about a broken table or report.
-
Metadata search – ability to find data assets (tables, columns, BI reports) by associated descriptions and properties (e.g. if I am a data scientist at Lyft and I want to find source of truth for rides, that’d be search for “rides”, rank by total # of queries that access the table).
-
**Data profiling **– as basic as it sounds, why do we need to type a bunch of SQL just to understand the basic properties of a column such as % of NULLs, uniqueness, and the histogram of values? Such information should be at every data practitioner’s fingertips. It is quite basic, but not knowing it can result in making dull mistakes that turn out to be costly to the business.
-
**Monitoring / Alerting **– most data environments are live, meaning they are subject to updates, outages, and bugs. Getting timely notifications when data in a particular table or column looks anomalous allows you to fix issues or notify people about the problem before anyone gets surprised. Datafold packages all these capabilities into one platform and integrates them with the modern data stack.
## Datafold for Everyone When we started working on Datafold with Alex two years ago, we thought that we’d be catering to large data teams at high-growth tech companies. What we discovered since then is that data teams at much earlier stage companies (or earlier stages of data adoption at established companies) have similar needs.It turned out that everyone experienced the same pains. And while larger teams would have the pain at a larger scale (i.e. larger total productivity loss), the pain is as acute for smaller teams in terms of preventing them from accomplishing more.
Tools such as Data Diff, Column-level Lineage, Catalog, and Alerting should be available to every data team.
We wouldn’t be able to do that if we were to stick to our top-down sales motion: when you have to hop on a call with a member of our Sales team, have follow up conversations, etc, – this not only adds friction but is also quite expensive on our end, so this can only work for big-ish ($40K+ deals). We understand that at such a pricing point, the majority of data teams wouldn’t be able to afford such tooling.
So I am excited to announce the launch of new set of plans:
-
Free tier that allows a small team using a Modern Data Stack (cloud DWH + dbt) to get column-level lineage and automated testing with Data Diff.
-
Cloud tier that offers powerful functionality at a larger scale with the pricing growing with the usage of Datafold and the complexity of the data Datafold monitors, starting at $799 / month when billed annually.
-
Enterprise tier for larger customers who have special needs such as in-VPC/on-premise deployment, custom SLAs and dedicated support. Excited to help more people have a more enjoyable productive data/analytics engineering experience! Get started with Datafold today!


