Datafold + dbt: Ship Better Data
Datafold has partnered with dbt Labs and has launched an integration with dbt to deliver column-level lineage, data diff, and shareable impact reports for analytics engineers.


document.addEventListener(‘DOMContentLoaded’, function(){ if(window.location.origin.startsWith(“https://datafold.webflow.io”)) { window.location.href = “https://www.datafold.com/blog/datafold-dbt-ship-better-data” }});dbt Labs has been leading the Analytics Engineering movement and enabled data developers with a user-friendly approach to building SQL data pipelines that elegantly incorporates some of the most important principles of agile software engineering, such as:
- Unified structure for data transformation (SQL + Jinja templating)
- Version control for source code
- Automated data “unit testing”
- Documentation that lives with code These principles have improved the usability of data within the warehouse which has enabled significantly more use cases to be built on top of it:

This explosion in leverage has put the focus on data being high quality since it is powering not only internal reporting but customer experiences and financially impactful algorithms.
To deliver high quality data we need to deeply understand how our data is connected (i.e. where it comes from and where it goes), be able to identify issues before data goes to production, and be able to bring in people with the right context to verify data is accurate.
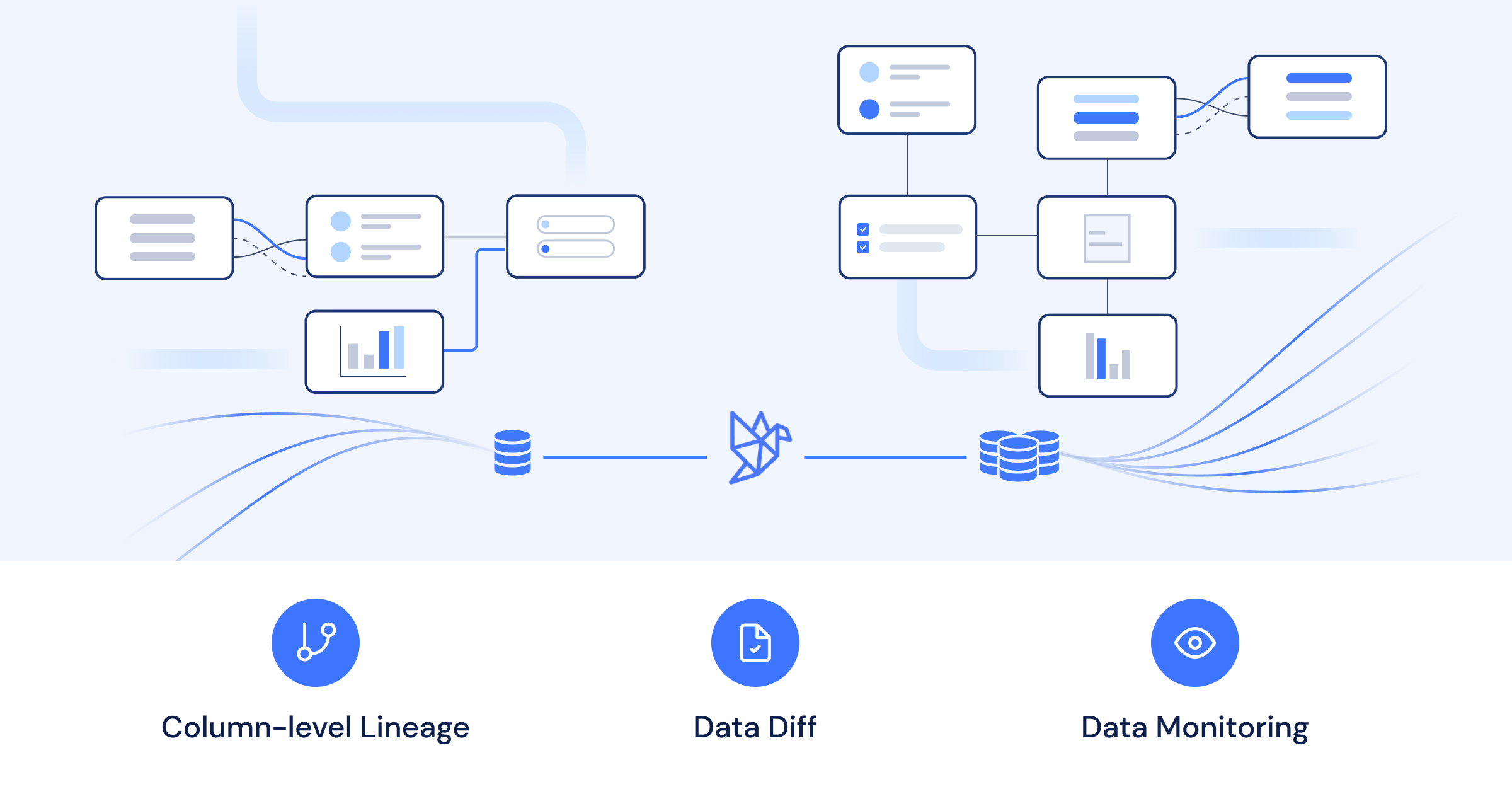
Datafold is excited to announce our partnership with dbt Labs and launching our integration to deliver that:
- Column-level lineage for all dbt models maps dependencies between tables and columns to show how data is produced, transformed, and consumed.
- Data Diff for dbt empowers the analytics engineer to see how dbt model updates impact the data in the modified table and downstream dependencies directly in Github or Gitlab.
- Shareable impact reports make it easy for marketing, finance, or stakeholders to review data and metrics changes before anything is merged to production. It’s a one-click integration with dbt Cloud, and for teams hosting dbt Core themselves, we provide an SDK to run within a CI pipeline.
Follow the discussion in dbt Slack, watch the demo, or book a live demo to learn more!
Column-level lineage for dbt
Using SQL files and metadata from the data warehouse, Datafold constructs a global dependency graph for all your data, from events to your BI tool and reports:
We have built lineage graphs of over 2 million tables with over 55 million columns. We also developed a powerful UI that makes exploring complex lineage graph intuitive. On top of this column-level lineage we can give analytics engineers insight about how their updates to dbt models impact the entire dbt pipeline all the way to BI reports.
Data Diff for dbt
With Data Diff, you now have the ability to see how a change to a dbt model affects the data in that modified table as well as its downstream tables and BI reports.
This allows you to **deal with data quality in your pull request **instead of scrambling to fix issues that already affected production.
This is especially powerful as dbt pipelines grow in complexity and small upstream changes can have surprising impacts in downstream tables and BI reports you are unfamiliar with.

Shareable Impact Reports
Seeing the impacts to tables is valuable, however it is often difficult to know if the impact is expected or not. Datafold makes it simple to share a report with your stakeholders detailing how metrics and column distributions are changing and what the row level impacts are.
Any team within the company can quickly review and vet this before the change goes into production. This makes the data team and other teams like finance and marketing partners in delivering high quality data.
Want to give it a try? Schedule a demo here to see it in action.