

Choosing Data Warehouse for Analytics
Objective criteria and subjective advice when choosing a data warehouse for analytics.


The role of a data warehouse (DWH) in data-driven (i.e. actively using data to power human and machine decisions) organization is to accommodate all analytical data, to enable its transformation, and to provide easy and reasonably fast access to people and systems that need that data.
DWH, thus, plays a central role in the data ecosystem. It is also often the most expensive piece of data infra to replace, so it’s important to choose the right solution that can work well for at least 7 years. Since analytics is used to power important business decisions, picking the wrong DWH is a sure way to create a costly bottleneck for your business.
Yet, I see so many teams make decisions on such a critical piece of infrastructure simply following their gut instinct or because “AWS offers it already” or “Facebook uses it” or “that’s what we used at X”.
In this post, I propose six dimensions for evaluating a data warehousing solution and offer my subjective opinion that BigQuery and Snowflake are the best options for a typical analytical use case and company.
Data warehouse use cases
Typically, the use cases for a DWH fall into three major categories:
- Ingest & store all analytical data – that you use now and may use in the future
- Execute data transformations (the “T” of “ELT”) Serve data to consumers:
- Dashboards
- Ad-hoc analysis
- ML pipelines Use cases NOT in scope:
Ultra-fast queries: (90% of queries < 5 seconds) e.g. for interactive exploration. Such speed typically requires trading off other important aspects such as scalability, so it’s best to use specialized solutions such as QuestDB, Clickhouse, or Druid
Specialized (e.g. geospatial or graph) transformations & ML jobs – there are excellent compute engines like Spark that you leverage to perform a specific type of computation.
Data warehouse requirements
- Scalability: fit all data & queries you need, scale storage & compute independently
- Price elasticity: only pay for what you are using
- Interoperability: seamlessly integrate with the rest of the data infrastructure
- Querying & transformation features: end-user delight
- Speed: just fast enough
- 0-maintenance: let your team focus on the right thing
Scalability
As obvious as it may sound, it’s important to pick a DWH that can accommodate as much data and workload as you have now and will have in the future. Data volume grows much faster than the business.
Businesses that choose poorly scalable data warehouses, such as Redshift, pay an enormous tax on their productivity once their DWH cannot grow anymore: queries get backlogged, users are blocked and the company is forced to migrate to a scalable DWH, and at that point, it’s already too late: the migrations are slow (years), painful and almost never complete.
If you are doing a migration at the moment, the following tools may help: CompilerWorks – is a SQL transpiler that lets you instantly convert ETL code between database flavors. Datafold offers a Data Diff feature to instantly compare old vs. new versions of the table.
Importantly, choosing a scalable DWH does not mean paying upfront for capacity that you don’t use: the best products allow you to start almost at $0 and scale as your data grows.
The three components to scalability
Storage
Fit all data that you collect (or will collect), be it terabytes, petabytes or exabytes, with costs growing linearly (i.e. doubling the storage should be not more than 2x more expensive).
Compute
There are different types of computational jobs that your DWH needs to run including ingesting, transforming, serving the data.
Compute scalability means:
- As many queries as needed can run concurrently without slowing each other down
- It is generally possible to shorten execution time by increasing the amount of resources Red flag: Avoid DWHs that have a physical limit to storage or concurrent queries capacity. “We’ll think about the larger scale once we get there” approach likely means engaging a time bomb.
Decoupled Storage & Compute
As your business grows, you want to be able to add more space to store data or support a larger number of concurrent queries. Systems that couple storage with compute – i.e. data is stored physically on the same nodes that perform the computation (e.g. Druid & Redshift) – are typically much more expensive to scale, and sometimes have hard limits on either compute or storage scalability.
Price Elasticity
Price elasticity means paying for you use, and the opposite: not paying for excess capacity and idling resources.
Here’s the summary of the pricing structures of the popular DWH products:
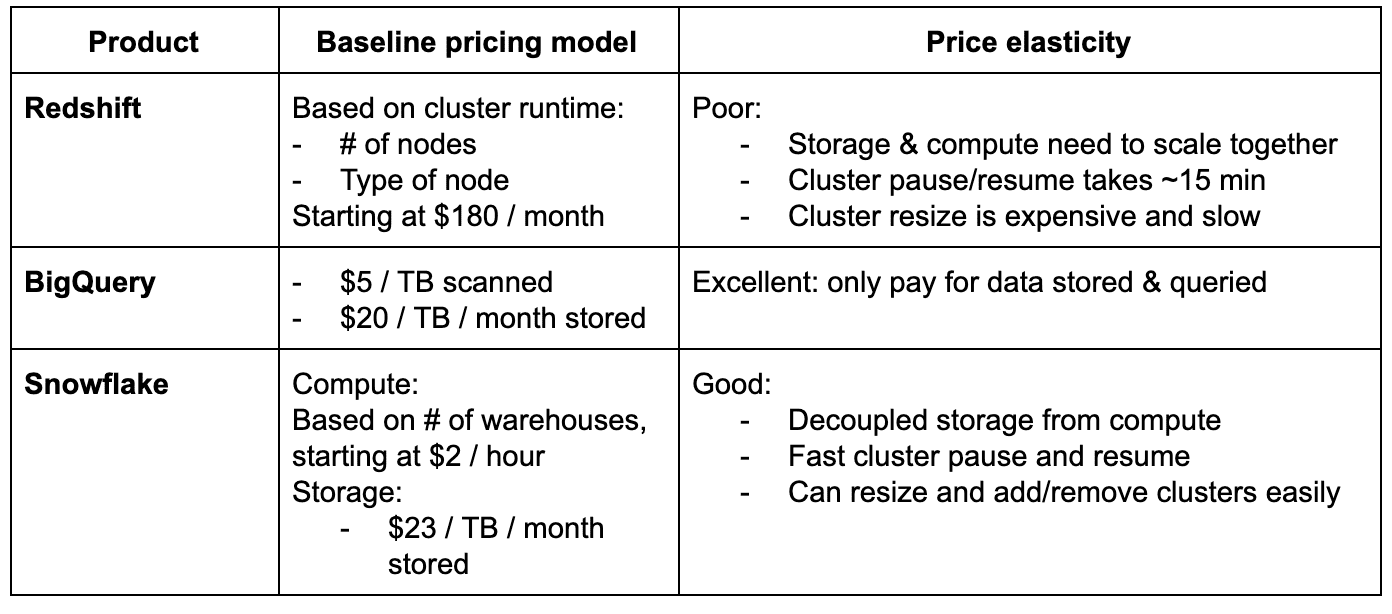
Comparing different pricing models is hard, and various benchmarks report different results. However, from a purely structural perspective, usage-based pricing (based on the volume of data stored and queried) is superior to time-based pricing:
You don’t pay for what you don’t use which is important as analytical load typically comes in bursts:
- Morning spikes when data users open & refresh their dashboards
- Nightly massive ETL runs Fivetran’s survey reported that an average Redshift cluster is idling 82% of time
- Usage-based pricing aligns vendor’s incentives in your best interest by forcing them to increase efficiency (i.e. speed) of their software. For example, since BigQuery charges you a fixed amount of money for a TB of data processed, it is in their best interest to process the query as fast as possible to lower their infrastructure costs. In contrast, vendors that charge you for provisioned infrastructure, e.g. Redshift or charge a markup on top of provisioned infrastructure, e.g. Databricks, Qubole etc. benefit from you using more resources less efficiently.
- Usage-based pricing provides a clear path to optimization: use less – pay less. Simple tactics such as eliminating redundant subqueries in ETL, adding filters to dashboards are immediately effective in reducing costs.
Interoperability
Simply put, easy to get data in and out. By picking a solution that is supported by the major collection, integration, and BI vendors, you will save yourself from a lot of headaches.
Querying & transformation features
The requirements here depend a lot on the use case, but for typical data preparation and analytics tasks, SQL is the most commonly used expression language. We recommend choosing a data warehouse that has first-class support for SQL and supports most frequently used aggregation functions.
Simplicity vs. flexibility Some systems expose interfaces for tuning the performance. For example, Hive has over 250 parameters that are adjustable for every query. This number is clearly beyond any human’s capacity to effectively work with and thus usually massively complicates the query development process for an average user.
Speed
Counterintuitively, over-optimizing for query execution speed when choosing a DWH can lead you in the wrong direction. Provided that the DWH is scalable – i.e. can run an arbitrary number of queries concurrently – speed is truly important only during the query development process. For example, when an analyst is building a report or a data engineer is building a new ETL job, every query run blocks their workflow. However, when the query is ready, i.e. proven to work on a small data volume and is ready to be executed against the entire dataset, speed doesn’t matter as much, as the user can switch to other tasks.
I suggest the following targets as a guideline:
- Queries should fail fast: syntax and semantic errors returning in < 2 seconds. For example, if you misspelled a column name, there is no reason to wait 30 seconds to learn about it.
- Fast prototyping on small (< 10GB) data volume: 90% of queries should execute within 10 seconds. For production runs, what matters is predictable query runtime so that the data pipelines can meet SLAs.
At a tera/petabyte scale, data warehousing is all about tradeoffs. You can’t get infinite scalability and sub-second query speeds at the same time. Although, the best products such as Snowflake come close with their smart caching techniques. Instead, shoot for “good enough” speed that can be maintained no matter how big your data and your team grows.
 Fivetran’s TPC-DS benchmark shows that most mainstream engines are roughly in the same ballpark in terms of performance.
Fivetran’s TPC-DS benchmark shows that most mainstream engines are roughly in the same ballpark in terms of performance.
There can be use cases where speed is the most important factor (such as for interactive dashboards). In this case, you should choose systems optimized specifically for serving queries super fast, such as Druid or Clickhouse.
0-maintenance
Modern data warehouses are complex and distributed software that is non-trivial to deploy and run let alone to develop. If you are tempted to go for a new shiny open-source engine, make sure to account for full cost of ownership and carefully evaluate the use case and trade-offs. I recommend going as serverless as possible and focus your attention and engineering resources on building your customer-facing product. Data warehousing in 2020 is a well-commoditized technology, and, unless you are really big to harvest economies of scale, most likely hosting a DWH yourself is a worse option economically.
Also be mindful that while some products such as Redshift market themselves as “database as a service”, they still require a non-trivial amount of ops work: vacuuming, compressing, resizing the cluster can easily require a full-time engineer or two to support.
Conclusion
Ultimately, it seems that for the vast majority of companies, BigQuery & Snowflake are the best data warehousing options. Both are infinitely scalable, require no devops or maintenance, are reasonably fast, offer first-class support for SQL, and work well with the best BI & ETL tools.
Some important distinctions:
- BigQuery is offered only in Google Cloud, and if your entire stack is in AWS, you may pay a larger tax on data transfer.
- BigQuery is truly serverless and charges per unit of work, whereas Snowflake has a concept of warehouses and charges for time, although it’s still very easy to scale resources to match the load.
- Snowflake seems to beat BigQuery when it comes to speed, especially for repetitive queries and queries with JOINs.



