

Data Quality Meetup #7
Get an overview of the Data Quality Meetup #7. With speakers from Virgin Media O2, Convoy, Nixtla, Metaplane, and Doctolib, the event included lightning rounds on data contracts, data observability, real-time data-sharing, testing automation, and time-series forecasting.

Host: Gleb Mezhanskiy
Guests/Speakers: Chad Sanderson, Daniel Dicker, David Jayatillake, Michael Loh, Richard He, Ismail Addou and Max Mergenthaler.
Data Contracts
By: Chad Sanderson, Director of Data Science, Convoy

About Convoy
Convoy is a digital freight technology start-up, whereby our mission is to transport the world with endless capacity and zero waste. We find smarter ways to connect shippers with carriers while solving for waste in the freight industry. Essentially, we build technology to move millions of truckloads around the country through our connected network of carriers, saving money for shippers, increasing earnings for drivers and eliminating carbon waste for our planet. **
**
About Data Science at Convoy
Data quality is extremely important to Convoy - as our entire business is built on the data we’re getting from our customers, shippers and carriers. We leverage machine learning, various forms of automation and business intelligence to inform pretty much every single decision we make. To establish data integrity and quality, we implemented Data Contracts. Data Contracts are API-like agreements between Software Engineers who own services and Data Consumers that understand how the business works in order to generate well-modeled, high-quality, trusted, real-data. To learn more about Data Contracts, you can review in Chad’s newsletter on Substack here.
**We ran into some problems with the quality of our data and the trustworthiness of our decisions, which later prompted us to implement Data Contracts. **

Pre-Data Contracts, we had these big data dumps via non-consensual APIs arriving in Snowflake, whereby we were mass exporting batches from production tables that no software engineer really agreed to, followed by data producers not taking accountability for the data quality itself. This became a big mess, especially when we started moving to a more centralized system
To summarize our pain points:
- Producers don’t take accountability for data quality
- Producers are not aware how their data is being used
- It’s hard to understand what our data means
- The connections between data are not clear
- The ‘source of truth’ of our data is not really a source of truth
- Big cost to validate whether the data is correct or working
- Each question requires a lot of effort to answers
- Weeks of work that should have been hours/minutes
**The vehicle that we wanted to use needed to enable our engineering team to treat data like they treat our product, which meant providing data over the line as an API. We determined that the vehicle to facilitate this transition was a data contract. **
We chose data contracts as the right tool for the job because of four reasons:
- Data contracts define clear ownership on the upstream data
- Contracts facilitate the development of data products
- They provide a single surface for semantic definition
- Facilitate collaboration between data producers and data consumers
Our stance on moving towards Data Contracts was founded on four key principles:
- Science and analytics are first class consumers of production applications, and they should define what data they need through contracts
- Software engineers should treat data as a product (API), whereby pods take ownership over their source datasets
- Federated change management should facilitated agile evolution of the data model
- Meet teams where they are, the right product for the right maturity
**An awesome place to get started is referring back to the article we published - as Convoy now has roughly 320-350 contracts that are in production, with thousands of changes made to those contracts every month. **

- In our Development workflow, we focus on Protobuf as our contract definition surface, which is where you would define the schema
- **Next you can incorporate the contract into the CI/CD workflow, **as it checks the integration tests performed by the software engineer
- If those tests fail or you’re making a backwards incompatible change, then we can actually break the build if the data contract is not being met via abstractions
- Then you have the ability to publish schemas through the Kafka schema registry, and push it via Kafka through an entity topic into the warehouse The main takeaway is that data contracts are critical for production-grade data pipelines, but they are powerless unless they have an ability to be enforced. The goal is to eventually focus on the definition of the semantics and production systems, not just accepting what we’re getting from these more operational use cases.
**
Observability vs. Quality in Data** By: David Jayatillake, Head of Data at Metaplane
About Metaplane
Metaplane is the Datadog for data. Our observability platform saves engineering time and increases trust by letting data teams know when things break, what went wrong, and how to fix it. We do this by automatically monitoring modern data stacks from warehouses to BI dashboards, identifying abnormal behavior (e.g., lineage, volumes, distributions, freshness) then alerting the right people when things go wrong.
About Data Science at Metaplane
To quote Metaplane’s CEO, Kevin Hu, he says “In software, there is a line which goes ‘treat software like cattle, not like pets.’ Unfortunately in the data world, we have to treat data like thoroughbred racehorses, because lineage matters”. What we should be thinking about is the quality and observability approaches that we can take to prevent data going into the red zone.
Today, data is becoming a product. Modern data teams centralize, transform and expose increasing amounts of data for increasingly many stakeholders and increasingly diverse use cases across machine learning, product experience, in-session actions and business intelligence. But more data, more problems.
Things inevitably break, leading to:
- Poor decision-making by stakeholders
- Lost trust by the organization
- Lost time for the data team
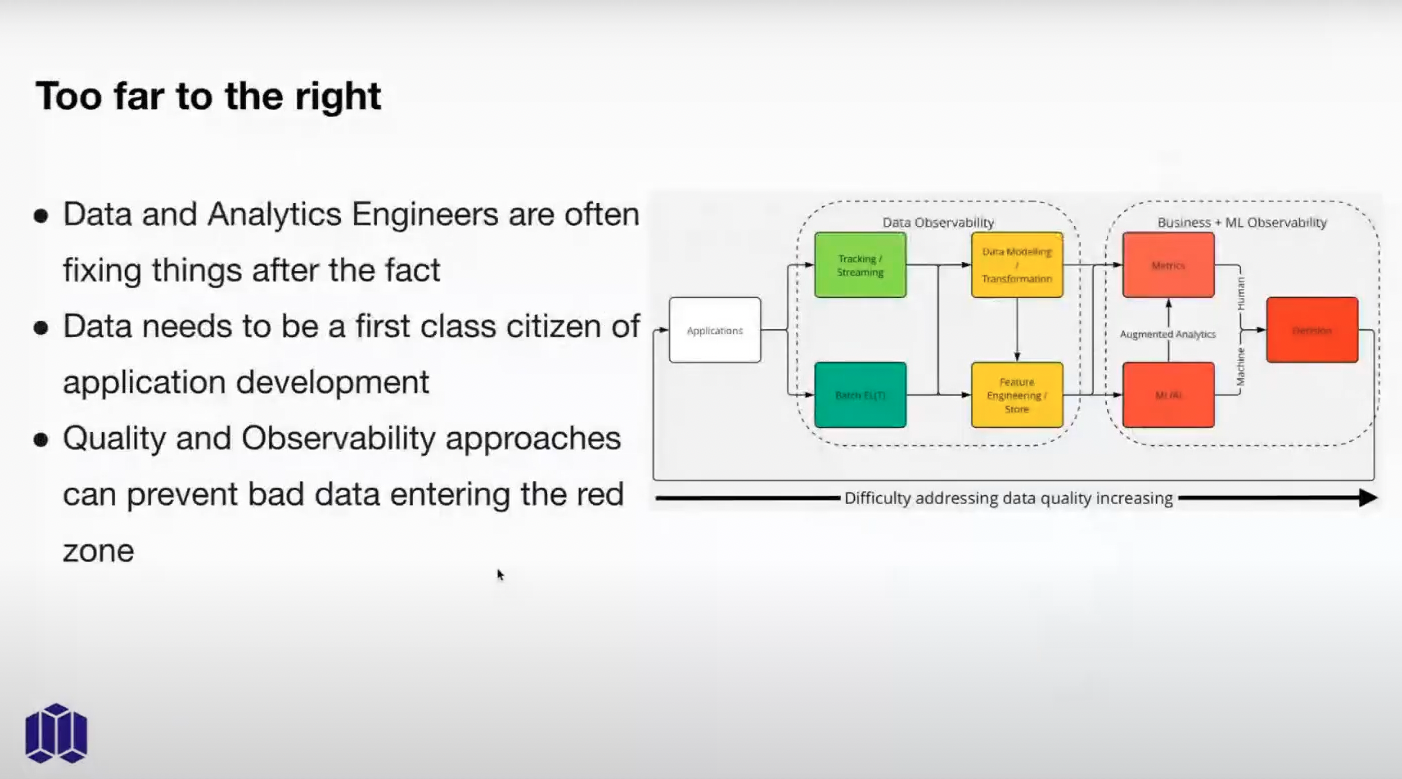
If the trust erodes because stakeholders see broken data or they make the wrong decision as a result of broken data, then the impact of data in an organization gets reduced, which is the exact opposite that we want as a community. Data and analytics engineers are fixing things after the fact, when in reality data needs to be a first-class citizen of application development within the CI/CD funnel. What we should be thinking about is trying to move further to the left of the diagram to improve quality. There are quality and observability approaches that we can take to prevent data going into the red zone.
**Data Observability as a solution is really interesting in the context of testing, as it monitors trends of scalar values; for instance, where you have a table with a foreign key. There is going to be some tolerance, a statistical significance where if you’ve reached that - it’s probably an anomaly and it could be a data quality issue. **

Metaplane’s Data Observability tool tracks several key components, such as:
- Freshness: how recently your data has been updated
- Data Sync: what you need or what you’d expect has appeared
- Historical patterns: have patterns in data anomalies happened in the past Data Observability is something that we need to actually invest in as a profession because it’s unavoidable if we need quality. There’s a similar parallel in Software Engineering, whereby test suites are a huge part of the cost of building. As we’ve all seen, engineers who changed one line of code will then check 40 lines of tests.
**Going forward, you can use data observability tools to test different datasets from different environments to see if there’s a possible data quality issue. **
I don’t know a CTO who hasn’t invested in Relic, Datadog, or an incident.io. They all have a test suite which also includes observability. Increasingly, there are other capabilities that can be inserted into your CI/CD workflow, such as Datafold’s Data Diff, to check for problems between what you’ve proposed in your code and what already exists in production, including upstream and downstream dependencies.
** **A standardized, scalable way for sharing data in real-time
By: Michael Loh, Data Engineer at Virgin Media O2
About Virgin Mobile O2
Virgin Media O2 combines the U.K.’s largest and most reliable mobile network with a broadband network offering the fastest, widely-available broadband speeds. We’re a customer-first organization that brings a range of connectivity services together in one place with a clear mission: to upgrade the U.K. We are the corporate brand of the 50:50 joint venture between Liberty Global and Telefónica SA, and are one of the U.K.’s largest businesses. **
**
About Data Science at Virgin Mobile O2
After the joint venture occurred, we set the objective of using data to elevate our customer experience. We’ve sought to centralize all our data in the cloud and hopefully make the right data accessible to relevant stakeholders for them to actually build platforms to serve the customers in more intelligent ways.
**Our Data Ingestion Platform, called the Vortex Engine, is what we built that enables a standardized, scalable way for sharing data in real-time using Google Cloud Platform (GCP). **
The end-to-end process begins with data flowing from the various sources (e.g., customer platforms, privacy management, microservices, web analytics), into the Vortex Engine, which then pushes data to the consumption layer for analytics and operational purposes. For this discussion, we’ll focus on how we designed our Vortex Engine for data ingestion.
The criteria for our Vortex Engine consisted of:
- Rapidly ingest API data
- Handle real-time event and batch ingestion
- Be a generic service of high scalability to serve different target destinations
- Contain and limit the amount of cloud infrastructure built

Our Vortex Engine can then be further broken down into three components:
- Left side is the ingestion methods
- Middle is the messaging queue
- Right side is the data processing for the analytics pipeline
- Ingested through the cloud run or cloud composer
- The payload from these services are packaged and published to a message queue before sending to either the analytical or operational pipelines
- For the analytical pipeline, we have a data processing component that actually only does light transformations before determining and pushing the message to the destination tables in BigQuery Data Lake
Ingestion: comprised of two functions - the Cloud Composer and the Cloud Run.
-
Cloud Composer: Data sources that require APIs for ingestion are orchestrated by Cloud Composer, which is a fully-managed workflow orchestration service built on-top of Apache Airflow. We manage this directly via a framework built on-top of Airflow, to fetch and publish payload to downstream pop-up topics. For us, these messages follow a generic Json message structure that we predefined.
-
Cloud Run: All real-time event-based integration messages are sent to a single Cloud Run API service, which publishes the same pop-up topics as for Cloud Composer, meaning this service also enforces the same consistent, generic Json structure.

**Message Queue: We leverage the Pub/Sub topic to enable our message queue for both analytical and operational consumers. **
We use PubSub for three reasons:
- To establish a one-to-many publisher-subscriber relationship
- To enable subscription with filtered messages
- To enable parallel downstream analytics and operational consumers
Our goal is to distribute different messages to different subscriptions, whereby these applications can utilize or filter messages based on the topic - using a given attribute, so that different operational consumers downstream are able to retrieve the data relevant for them. In parallel, these messages will be processed by the analytical pipeline to store in the BigQuery Data Lake. As for the analytical pipeline portion, we chose cloud data flow for data processing so that it’s able to handle a large amount of streaming messages by auto-scaling the number of workers. To add, we chose to deploy our own custom data flow pipeline, as the one that was provided by Google could only handle a single source to a single BigQuery table output

**Data Processing: we are able to determine where these messages will land based on an identifier that is created to enable look-ups in the BigQuery table ID, via the site input and eventually writes the message to the respective table. **
To accomplish this, the Data Processing Layer is comprised of three dataflow jobs:
- Handles large amounts of streaming messages
- Includes a custom dataflow pipeline: includes multiple source data to different destination tables and dead letter queue
- Metadata Management Service: includes UUID, BQ Target Tables and a Metadata Table
If there is any validation required within the dataflow job or if tables are invalid, then the message will actually be sent to this additional pop-up topic, for which we can actually reprocess again.

**
To test the Vortex Engine’s capabilities managing the analytical pipelines, we ran some tests. ** One example, on the top-left-hand side, we ran a simple load test of about 4,000 event messages sent to the cloud run service over a two-minute period, with a single dataflow worker and we can see that we’re able to actually make these messages before 50 percentile in about 7 seconds - which you can see in the PubSub - Ack Latency Load Test graph.

**CI Pipeline for data warehouse - test automation for SQL redshift queries **
By: Ismail Addou, Data Engineer at Doctolib
About Doctolib
Doctolib is primarily known as a booking app for healthcare teleconsultation services. But we’re also developing many other tools that offer a new work experience for doctors or healthcare practitioners, including enhancing the medical journey of Ppatients. Our company goal is to develop services and technologies to improve the journey for both patients and healthcare personnel.
About Data Science at Doctolib
Our Data Team today consists of ~40 individuals, working across many projects on AWS. My discussion is about data warehouses, as our Data Team is very active - pushing 25 commits per day and we try to keep the time to production less than one day. With this high velocity practice, there’s a high risk of pushing code errors. We use Redshift, which has some key constraints such as it’s a single point of failure, it’s a relational and strongly typed database, and we need migrations to add/alter/delete assets (e.g., columns, tables, schemas, views). In our data warehouse, we use many data marts that are dependent on each other in the same database, making them all vulnerable to failure at any point during the workflow.
Our core pain points consist of:
- Code mistakes
- Database conflicts
- Data sources structural changes
- Types overflows
**To address these challenges, there are two key steps we pursue.
The first step consists of pre-production tests whereby we re-run all the data workflows using real data.
**
 **
**
**
**
**The second step consists of having more effective tests to detect code mistakes and database conflicts in the CI pipeline. **
We moved from a detection approach in pre-production to a prevention approach. Before merging to the main branch, a CI process should test all the workflows to validate whether the PR should be merged or not. As a result, we will do the same tests as pre-production but without need of data so we can save time and drive faster tests.

We dedicated a new cluster with the minimal configuration possible, as we don’t need data or performance. For each PR, a CI is triggered and it creates a temporary database that is very similar to production but without data. So the best way to do that is to use DDL queries.
 **
**
**
**We implemented a homemade orchestrator based on Airflow Library to make it aware of task dependencies according to the tags, and also to expedite execution of the operators that are coded in Airflow inside the script. **

**Fast and Accurate time series forecasting with Nixtla **
By: Max Mergenthaler, CEO & Cofounder of Nixtla
About Nixtla
We are a startup that builds forecasting and time-series software for data scientists and developers. Classically, time-series was used for demand forecasting, supply chain optimization, electricity problems, etc. However, we’re now seeing a lot of growth in the observability and data quality space to detect anomalies, to forecast the future loads and to do infrastructure provisioning.**
**
About Data Science at Nixtla
In Python, there was a big missing link, namely a solid and robust alternative for statistical models. We decided to create a stats forecast, trying to bridge the gap between R and python. We ported a lot of what was done by a very famous practitioner called Rob Heinman and created the fastest version of RM out there, as well as the fastest and most robust version of ETS.
**We built our first model, ARIMA, which was nearly 40x faster than the leading Library called Profit, as well as 70% more accurate and substantially more cost-effective at $10 compared to $300. We showcased to the Profit community and received great engagement and feedback. **

However, after trying to resolve the first contradiction between R and Python, and creating a stat forecast, two new tensions arose:
- Namely, the classic tension between machine learning data science and classic statistics, or rather - the classic tension between interpretability versus accuracy.
- The second tension is expressed between the classical auto regressive models used by statistician econometricians and financial practitioners, as well as deep learning models. With this in mind, we’re contributing to the field with models that are not only very accurate and leverage the advantages of deep learning in terms of scalability, simplicity of pipelines, and accuracy, but are also in the line of composing the signal into different interpretable blocks. We accomplished this through the expansion of a very classical model called the N-bits, as well as with N-hits. They offer interpretable forecasting tools and decomposition of signals for long horizon forecasting.


Everything is open source, and it can be used and tested by different data practitioners. We created this other Library, called neural forecasting, where we included the models that we developed and probabilistic forecasting methods so the community can use them.
Panel Discussion

Panelists (from left to right, top to bottom)
- Richard He, Head of Data Platforms @ Virgin Media 02
- Max Mergenthaler, Co-founder and CEO @ Nixtla
- David Jayatillake, Head of Data @ Metaplane
- Gleb Mexhanskiy, [Moderator], Co-founder & CEO @ Datafold
- Daniel Dicker, Data Platform Lead Engineer @ Convoy
- Ismail Addou, Data Engineer @ Doctolib
- Michael Loh, Data Engineer @ Virgin Media 02
How do we think about the application of data contracts in: (1) conventional data platforms, so if you’re not running a complex architecture - how would data contracts apply to you, and (2) how do data contracts apply in the non-streaming world - (e.g., data contracts for data in Snowflake)
Daniel: Our first goal was to get data engineers and data science folks on the data side to come together and figure out what our production use cases were, then agree to what and how it was going to be produced. So for example, we wanted to take advantage of an abstraction layer where even if data engineers on the production-side wanted to change the underlying database, we could give them a surface to be able to emit or produce events in a standard shape that they had agreed to. We were able to use an existing streaming infrastructure set-up.
How does the concept of contracts, which is basically codified formal definitions of data assets produced throughout the pipeline - apply to the more classic modern data stack? For example, if we’re utilizing Fivetran Runner Stock, Airbyte data extraction, then using something like DBT in the cloud Warehouse.
**David: **For example, in a true batch process - if you’ve just run a query on the previous tables and created a new table. I think one of the ways you could implement a data contract in this example is to have a true unit test, because DBT tests currently are more like quality tests - they’re not unit tests. If you had a unit test where you said this model is actually a function and we have this static input that we’re going to pass into the function and we expect this static output, then you could actually say well this function meets the contract. This model meets the contract.
How should larger organizations approach change management given the amount of data, complexity and number of consumers downstream? To what exact are data contracts needed for reliable change management, especially in the context of a larger organization?
**Richard: **In Telecom, there’s lots of old school tech - there’s lots of databases like Oracle, DB2, mainframe, etc. But there are still modern technologies that can solve this problem. We use Shrimp on a lot of the on-prem, existing data sources from Oracle - so those are actually replicated by our binary logs using the trial files into BigQuery directly.
In my opinion around data contracts, it’s the easiest to be able to manage those binary logs - to make them automatic for the majority of use cases. Backwards incompatible changes, especially in a large organization from these databases, is extremely unlikely based on statistics we measure.
By harnessing new tools like Stream or Fivetran, and harnessing their binary log of changes, capturing it actually handles the schema changes very reliably - because all of these things are actually in the form of events.
I think it’s important to prioritize whether you actually can store the data in a semi-structured way. For example, BigQuery has recently announced something called a Json data type, where you can do tree-based lookups to even save your costs on that extreme risk cover, and then the information that’s not extremely important, you can get it ingested as Json data types, which you can just define as a schema afterwards. But for super critical data, such as customer data or transaction data, you probably don’t want to mess around with not having any contracts.
Who is responsible for instrumenting reliable change management and quality observability of data? Is it a platform team or is every data pod responsible for their own domain? Who takes responsibility for data quality and how is the function organized?
Richard: It’s decentralized because otherwise you can’t scale it as a function. Especially in large organizations, it just can’t be the centralized team doing everything. So in the approach we’re adopting, it’s key to define ownership for SMEs who then build policies in their area. If you build it, you own it.
**Ismail: **When something fails, everyone must share accountability. For example - at Doctolib, we have a ‘data system’ to protect ourselves, which detects the changes that could happen to the database from which we’re pulling data. So it’s a collaborative process with the software team and the data team just to detect those changes. We also have an automatic pull-request where you can change the structure, which prevents Redshift from failing in production and is a quasi-data contract for batch and streaming.
Daniel: So the platform team at Convoy develops the tooling that allows people to ensure data quality but then in the case of data contracts, the ownership of the end data products, so your machine learning models, your executive dashboards, etc. those are owned by folks on the data team. The people who are producing data for those kinds of critical production path pieces of data, like the data that is generated to train our pricing models at Convoy (e.g., how we price shipments), that is then owned by the software engineers.



