

Announcing Development Testing for dbt – Develop faster with higher confidence
Why we created a Development Testing suite for dbt and how to get started with the open source data-diff dbt integration, as well as a brief introduction of Datafold Cloud.


As of May 17, 2024, Datafold is no longer actively supporting or developing open source data-diff. For continued access to in-database and cross-database diffing, please check out our free trial of Datafold Cloud. We’re grateful to everyone who made contributions along the way. Please see our blog post for additional context on this decision. As a Data Engineer, I started Datafold to help engineers ship faster without compromising quality.
It always bugged me that while my queries ran faster and faster on the cloud warehouses, it still took me forever to ship my work because of how long the testing, validation, and review process was. When I skipped the validation, things often didn’t end up well.
From the founding story of Datafold:
“Early in my career, as an on-call data engineer at Lyft, I accidentally introduced a breaking code change while attempting to ship a hotfix at 4AM to a SQL job that computed tables for core business analytics. A seemingly small change in filtering logic ended up corrupting data for all downstream pipelines and breaking dashboards for the entire company. Apart from being a silly mistake, this highlighted the lack of proper tooling for testing changes. If there had been a way to quickly compare the data computed by production code vs. the hotfix branch, I would have immediately spotted the alarming divergence and avoided merging the breaking change.”
Just don’t break it!
Data testing is broken.
How do you improve it? Writing proper unit tests for SQL is notoriously hard, as SQL isn’t composable. “wet” tests like dbt tests or great_expectations are helpful in some instances but become noisy and unmanageable at a large scale.
In my experience, the biggest problem for data validation is that data developers lack full visibility into the impact of their code changes on the data this code produces. It’s hard enough to make sure your code generates the proper dataset output, but in a modern data team, you also need to worry about how the data you produce is used downstream.
Marketing asks you to adjust the duration of user session, and a month later Finance tells you that they’ve reported wrong numbers to the board because your change recalculated the conversion rates they’ve been reporting to the board.
To solve this problem with better visibility, we need two fundamental technologies:
-
Data Diff to compare the data before and after the change
-
Data Lineage to trace how each data point is produced and consumed in an organization With data diff and column-level lineage, we can then answer the questions:
-
How will a given change to code (SQL, dbt, etc.) affect the output data in the dataset I modified? (data diff)
-
What downstream datasets and data applications (e.g. BI reports, reverse ETL syncs) will the change affect? (lineage)
-
How will the data change in those downstream applications? (data diff, again) That makes sense, but how do I integrate this into the data developer’s workflow?
Deployment Testing as guardrails for the data team
Borrowing from the field of software engineering – testing that is not automated is not getting done – the best way to apply such testing is during the deployment process:
- Data developer opens a pull/merge request with the proposed code change
- CI/CD pipeline runs the new code and creates a staging environment
- Datafold diffs the staging against production (source of truth) for the modified dataset and its downstream dependencies. The resulting analysis is printed back in the pull request.
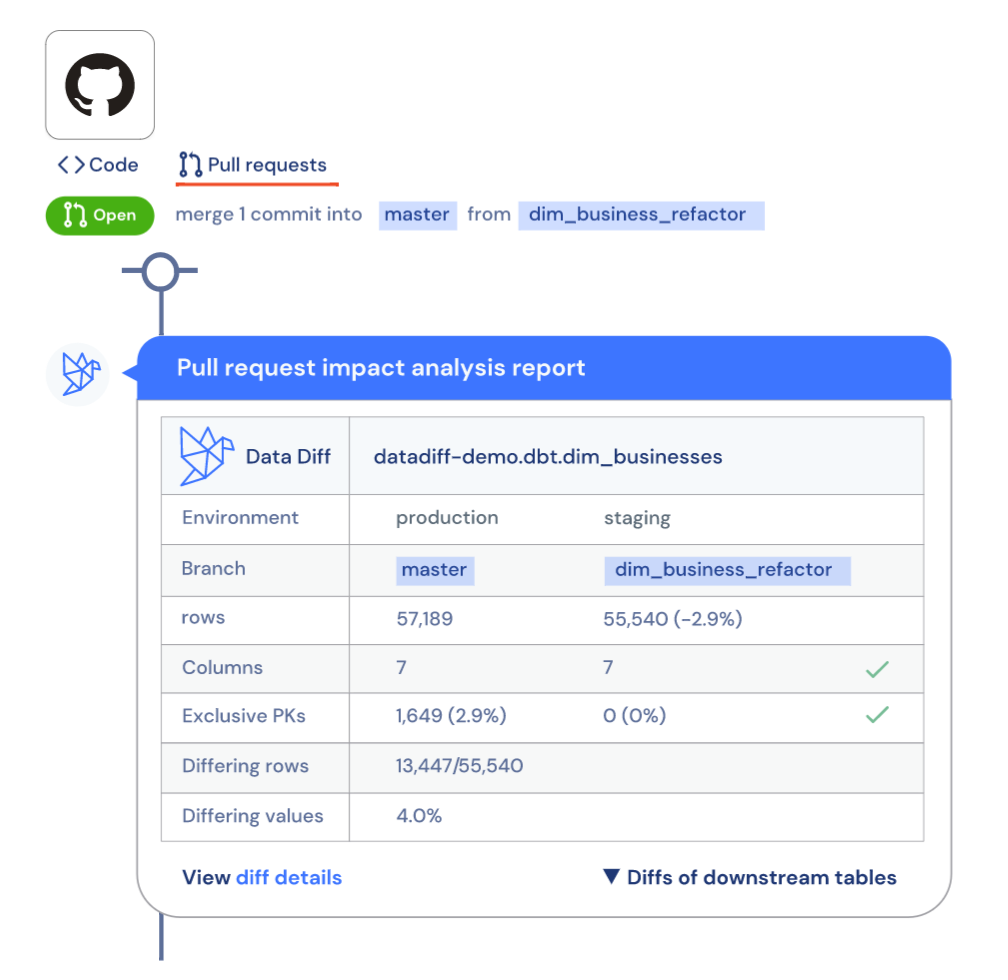 As a result, data developer, their peers (code reviewers), and stakeholders can all be on the same page regarding the change.
As a result, data developer, their peers (code reviewers), and stakeholders can all be on the same page regarding the change.
That worked very well! Over the last 3 years, we’ve enabled some of the leading data teams with automated pre-production testing of their code changes, helping them quickly identify any regressions and reach closer alignment with the data consumers about the evolution of the data products.
Shifting testing further left
As we introduced automated data testing to increasingly more teams, we noticed that our users were interested in pushing testing further to the left – earlier – in their development workflow. They wanted to test their code while they were writing it. Some would even open “fake” pull requests just to have Datafold run the checks!
Validating work quickly during development allows data and analytics engineers to avoid errors and breaking changes early in the process and avoid expensive and frustrating refactorings and back-and-forths during code reviews.
This is not surprising – shift-left testing has been a major trend in software engineering, where modern IDEs and individual dev environments allow engineers to catch errors and smoke-test their code continuously as they develop.
A few months ago, we open-sourced data-diff – a CLI library with a Python interface that enables efficient data comparison within or across databases at any scale. We believe that diffing is a fundamental capability in the data engineering workflow, and we saw the tool picked up by different teams to solve various day-to-day problems.
And while the tool is applicable to various use cases, we know an efficient workflow is more than just comparing data. Excellent data quality is a byproduct of an efficient workflow.
Development Testing for dbt. Fast, simple, and free.
I am excited to introduce the Development Testing suite by Datafold – data-diff CLI that readily integrates with dbt – the leading platform for transforming data in the data warehouse.
It lets you, as a data engineer, quickly validate your code by diffing its data output against production data or against the previous iteration.
It also integrates with dbt and automagically picks up the changes from the latest local dbt run so that you can quickly validate your code as you develop.
In a standalone mode, the open-source data-diff CLI performs diffing using locally configured database connections and provides basic stats about the change:
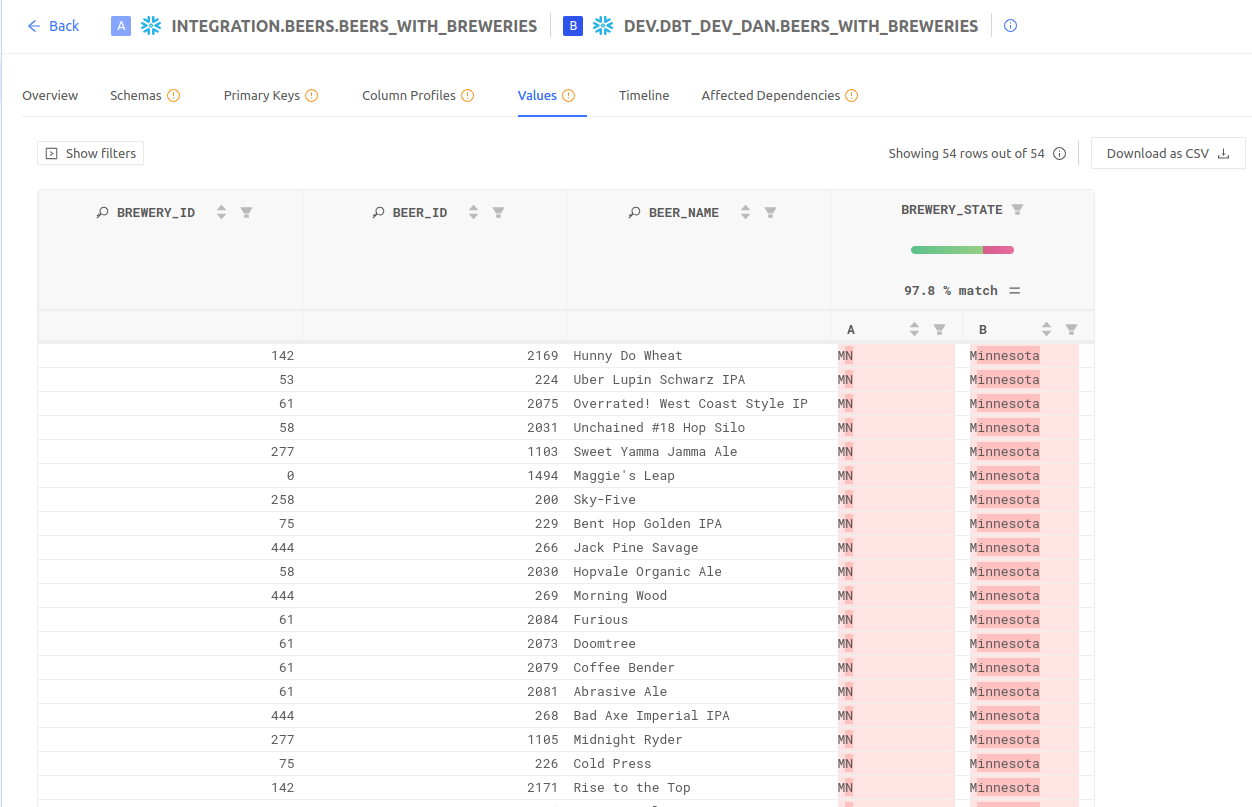
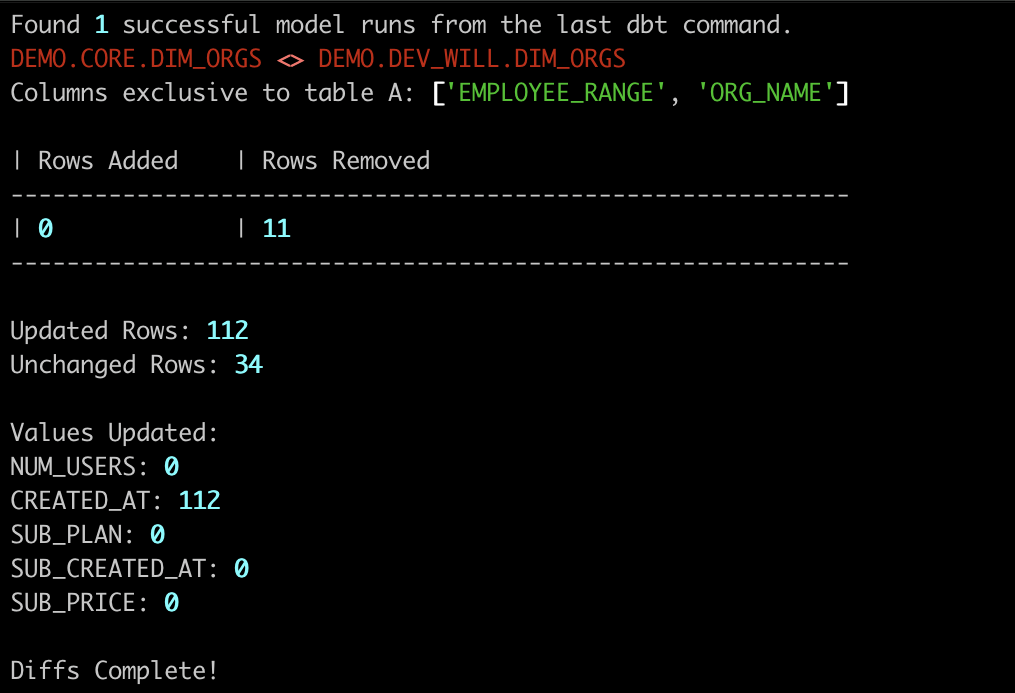 Integrated with Datafold Cloud via an API key, the CLI provides rich insights and allows you to share diffs with your team and stakeholders.
Integrated with Datafold Cloud via an API key, the CLI provides rich insights and allows you to share diffs with your team and stakeholders.
We want to empower every data engineer with tools that allow them to move faster with higher confidence.
 If you are a technical or team lead interested in preventing bad dbt deploys for the entire team – let’s chat!
If you are a technical or team lead interested in preventing bad dbt deploys for the entire team – let’s chat!
This is only the beginning – we have so much to improve in the data engineering workflow. If you’d like to stay up-to-date with our new developments and my data engineering speculation – sign up for our newsletter.



