
What is data replication? And how to make sure you're doing it right






Data replication is the CMD+A, CMD+C, CMD+V of data work. And for the same reason as those commands, we replicate data to quickly copy something from one place to another.
In this blog post, we’re going to unpack:
- How data replication increases data reliability and accessibility,
- How data teams replicate data, and
- How validating replication efforts with Datafold unlocks unparalleled data peace of mind ✌️.
What is data replication?
Technically speaking, data replication is the process of copying data from one location (typically data already stored in a data warehouse) to another location. Data replication can happen in streams or batches, (near) real-time or not. Replication is usually accomplished through the use of ETL tooling or custom data engineering work.
Data replication use cases and benefits
Data teams replicate data to ensure their data consumers have the data they need—when and where they need it. In general, all data teams are conducting some form of replication, whether they call it that or not. Replication can look a few different ways:
- Almost all data teams replicate data from transactional databases managed by software engineers to their own data warehouses/databases/data lakes for analytics, data modeling, reporting, and advanced analytics purposes.
- For larger organizations, replicating data is an effective way to disseminate data across different teams and/or use cases. For example, the data science and machine learning team might not have access or use of Snowflake, but need the analytical data stored there by the central data team. As a result, teams will replicate data from Snowflake to the data science team’s storage center, such as Databricks.
- Data replication is also a way to help guarantee data reliability, security, and accessibility by having the data stored in multiple locations (usually across different regions). If there was ever a major outage in one region of storage, for example, data that was replicated in another location in another region could still be accessed and used by the organization. Also, if data is replicated across different regions, a team member in Europe can have quicker access to the data if it’s also stored in Europe versus directly querying data stored in North America.
This is by no means an exhaustive list of why organizations replicate data, but are some of the benefits and reasons for replicating data. Below, we’ll walk through how data teams replicate data and how Datafold is enabling teams to validate replicated data with speed.
How teams do data replication
The greatest considerations when deciding to replicate data is to decide between:
- ETL tools vs custom engineering work
- Batch vs streaming
ETL tools vs custom scripts
The crux of all replication is extracting data from one location and copying into another. Many data teams choose to use modern ETL tooling (e.g. Fivetran, Stitch, Airbyte) or custom EL (extraction-load) scripts to replicate data at scale. Below is a table overviewing common replication methods and tools.

In custom extraction and loading efforts, data engineers will typically either interact with a source destination’s API to pull and dump data into an external destination (say an S3 bucket) or copy the data directly into a new storage location (often also S3 buckets). For organizations that need replication to happen near real-time, engineers will leverage Kafka or Kinesis streams to extract and load data in a continuous motion. These scripts require data engineers and more technical data team members to build and manage them, especially with considerable data volume growth or real-time data needs.
Batch vs streaming
Another dimension to consider around data replication is whether you’re going to replicate your data in batches or streams.
- Batch: In batch replication, like the name would suggest, data is extracted and loaded in batches to your source destination. In a batch process, there are often delays in processing data at scale, making batch processing less “real-time,” but often less expensive since you’re running replication pipelines at set cadences.
- Streaming: When you replicate data via a streaming method, you’re constantly receiving new data in a, well, stream. Streaming data can yield more real-time results, but often at the cost of more expensive EL pipelines.
For the most part, we often see data teams leverage batch processing for their replication use cases. Most downstream use cases for data do not require real-time data, but can live with “real-ish” time data that can often be accomplished with cheaper batch processing run at regular intervals.
How to validate data replication with Datafold
When you replicate data across databases, you risk considerable data loss, corruption, or change. So how do you ensure the data you replicate matches your source data?
That’s where Datafold and data diffing come in.
Data diffing is the act of comparing two tables to check whether every value has changed, stayed the same, been added, or removed between the two tables. Think of it as a git diff, but for two tables in the same (or different) databases.
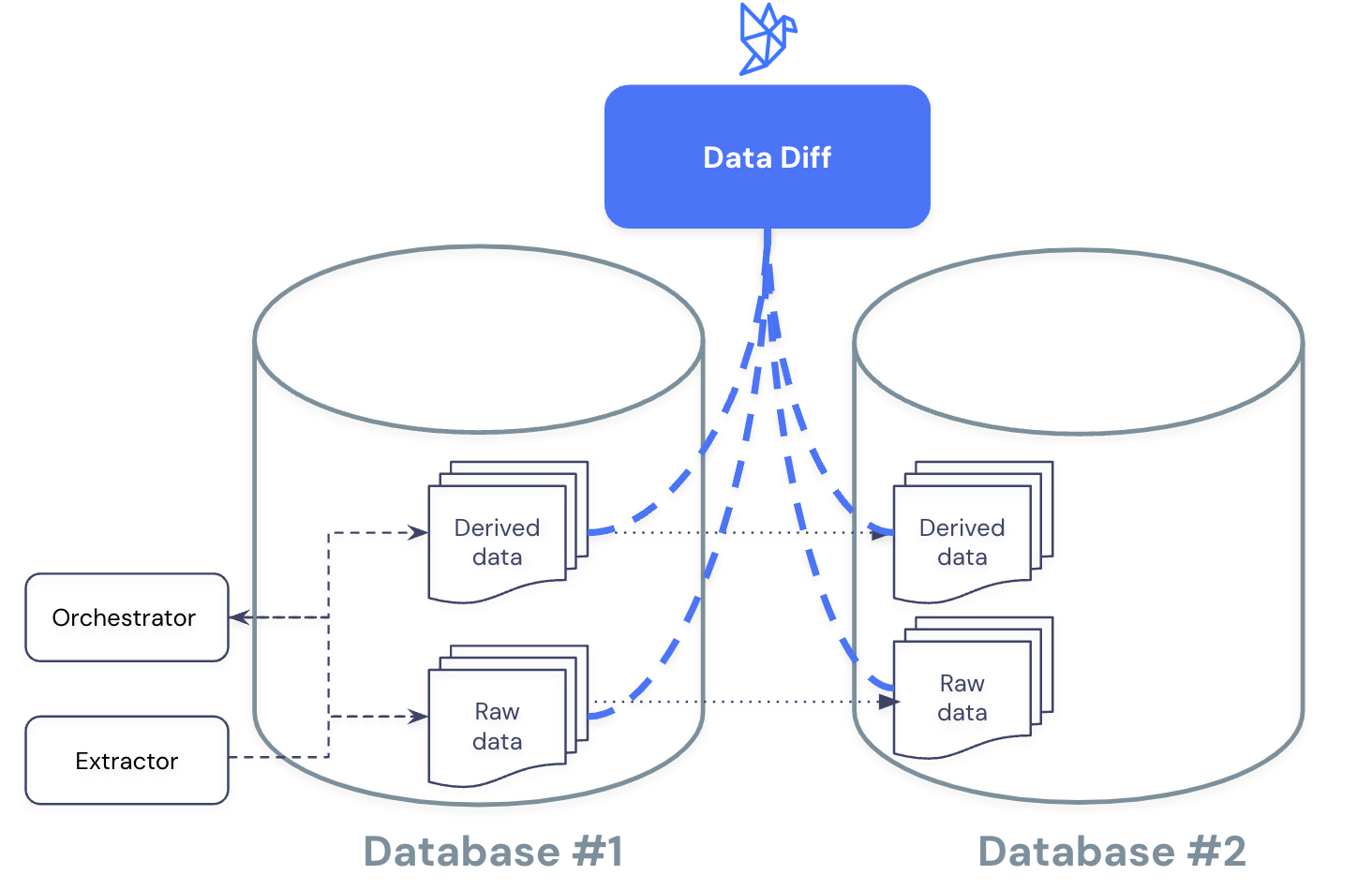
Using Datafold Cloud’s UI and REST API, you can find data diffs across different database objects in minutes—even if tables are millions or billions of rows. Datafold’s data diff results will be able to quickly tell you if tables are exactly the same or different. If they are different, you can investigate at the value-level using the Datafold UI to find out what exactly happened to your data during its “transit.”
In the example below, a diff between a beers table in Databricks and its replicated version in Snowflake was run using Datafold. The Datafold Cloud UI shows the specific column values that differed between the two.
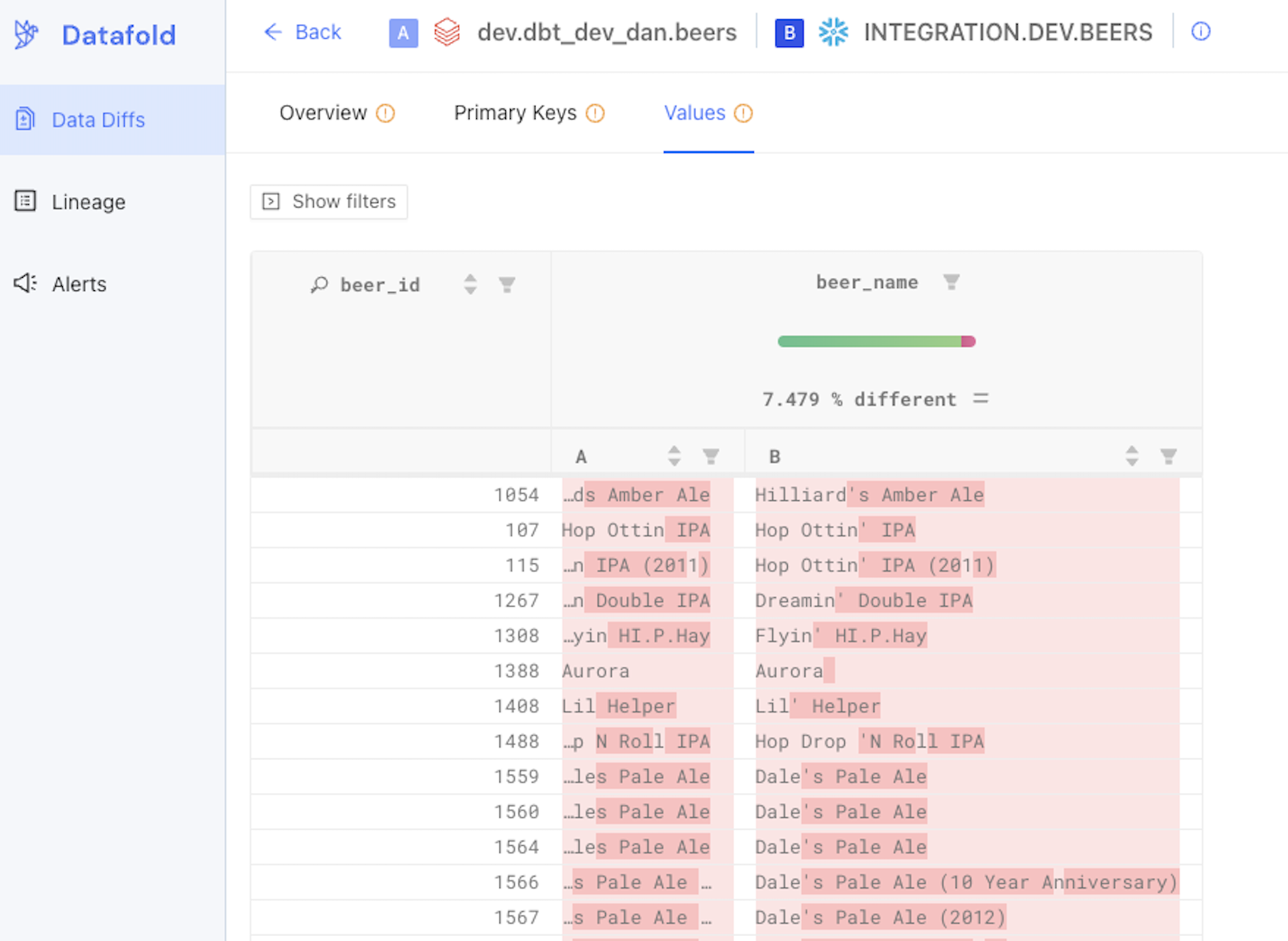
But why exactly is this a game-changer for teams undergoing regular replication?
Let’s back up a bit. Imagine a world without automated data diffing 🥶. If you were to try to ensure that a dim_customers table was the exact same in Snowflake as it was in your replicated BigQuery version, how would you go about doing that?
You could do try a few things:
- Run some ad hoc data profiling queries (check number of primary keys, rows, min and maxes for numerical columns, etc.) in each database
- Establish a set of assertions or tests you know to be true about your source data that you run on your destination data
- Tack on these queries and tests to your custom EL work, or run these tests on some sort of automated or orchestrated schedule
- …or just ship it and pray nothing went wrong 🙏?
Now imagine this scenario with regular row count increases (because thankfully you’re getting more customers), potentially changing schema designs, and…hundreds or thousands of tables you need to replicate.
Now with Datafold Cloud, you can run data diffs for your replicated data across databases in a scheduled, programmatic, or ad hoc way. This means no more assertion tests, weird increasing row count checks, and back-and-forth between two systems. With Datafold Cloud and data diffing, know immediately whether something has gone wrong during your replication process.
.png)
If you want to learn more about data replication and how Datafold Cloud will enable your team to replicate with confidence, reach out to our team today.
Conclusion
Data replication is the process of copying data from one location to another (typically across data warehouses) and happens on a continuous basis for many organizations. The primary use cases around data replication include increasing or guaranteeing data reliability, accessibility, and speed.
But it’s impossible to ignore it can be a technical feat to not only undergo replication on a regular cadence, but ensure the data you’re replicating matches that of your source system. Datafold, with its efficient cross-database diffing capabilities, enables your team to run regular replication with confidence.
To learn more about Datafold Cloud and how it’s helping teams automatically find data quality issues, check out the following resources:
- 📺 Join us for our next Datafold Cloud Demo Day, to see cross-database diffing in action
- ❓Get a demo from our team, so you can ask all your technical pressing questions to our team of product experts
Datafold is the fastest way to validate dbt model changes during development, deployment & migrations. Datafold allows data engineers to audit their work in minutes without writing tests or custom queries. Integrated into CI, Datafold enables data teams to deploy with full confidence, ship faster, and leave tedious QA and firefighting behind.