
Shifting Data Quality to the Left: A Four-Level Framework






Software testing has been a fundamental component of the software development life cycle (SDLC) for the last 40 years. Though the frameworks and methodologies for software testing have changed dramatically in the last four decades, the approach to data quality testing has not seen the same rate of change until recently.
In software development, we've seen testing become more rigorous and shift to the left — that is, shift toward earlier stages of the SDLC. In recent years, this same phenomenon has finally appeared within the domain of data engineering.
Why does it make sense to treat data quality similarly to software quality?
Today, all analytical data is created, transformed, and processed by the software, whether it’s SQL, dbt – data build tool, or sophisticated streaming services. Therefore, most data quality issues are, in fact, bugs in the software that processes data.
When organizations don’t adopt a shift-left data testing approach, data quality issues are often detected too late, which causes:
- Loss of trust from stakeholders and external clients toward the data itself
- Incorrect decision-making by stakeholders and business-level leadership.
- Degraded reliability of client-facing products that depend on the data produced by these systems.
The new approach to data quality assurance: shifting left
What does it mean to shift data quality assurance to the left?
Modern data development process follows the software development life cycle: data engineers develop data code, then deploy it to the systems that run the code, and continuously maintain data pipelines in production.
Shift-left data testing moves data quality assurance (QA) from stakeholders reporting bugs in their data applications to data monitoring, sending alerts to automated testing during deployment and development stages allowing data teams to move from being reactive to proactive by preventing data quality issues from occurring.
Why shift data quality assurance to the left?
The answer is very simple. If bad data makes it to production (i.e., is shown on a dashboard, is imported into Salesforce, is used in ML training), whether or not detected by stakeholders or data observability tools, it’s simply too late and too bad. By allowing data issues to enter production, we massively increase the burden on data teams and the cost of maintaining data products.

Four levels of shifting data quality to the left
Level 0: Stakeholders
Stakeholders who consume the data through BI or business apps identify problems in the data. Numbers look off in reports, charts fail to load, and bad decisions are made. The stakeholders alert the data team about these common data quality issues, usually via email or Slack with some hotly worded message. This is the least desirable outcome. This has started to erode trust in the data team from stakeholders, and worse, the issue may have been present for a long time before someone noticed. Issues found by stakeholders kick off a fire drill for data teams, who have first to find where the issue actually occurred in the pipelines and fix it quickly.
Level I: Data monitoring
Adding monitoring and alerting to identify anomalies in the data. Data teams get notified via Slack or email when anything looks abnormal in production, which allows them to respond to issues before stakeholders find out. This means bugs exist in production for less time, and it avoids the loss of trust seen in Level 0.
Adding data observability to production may seem like a good step toward improving data quality. The big problem with overly relying on data observability to solve data quality is that issues still occur in production, which means:
- Lots of issues that data teams need to triage and respond to, leading to alert fatigue
- By the time a data quality issue is detected and addressed, it may already affect a business decision
Fixing data quality issues once they make it to production means, once again, you are under the gun to get it done, and figuring out the root cause can be difficult and time-consuming.
Level II: Proactive data testing during deployment
Automated testing built into the deployment process allows data engineers to find issues before anything gets into production.
Modern data quality tooling allows data teams to ensure data reliability during the deployment process: when the changes to the code (e.g., SQL) are already made, and the code is about to (but hasn’t) been deployed to production.
It is the best stage in the development process to implement team-wide guidelines and automation to validate every change.
Three steps to implement proactive testing during deployment
Step 1: Implement version control for all data code
Proper data governance and data quality improvement are not possible if the code that transforms the data is not version-controlled. Luckily, most modern frameworks, orchestrators, and BI tools natively support version control for data-processing code.
Step 2: Implement data diff to validate the impact of every change on data and applications
With version control, we can tell how the code changes between iterations. What about the data itself? Knowing how the data changes when we change the code, no matter how small, helps data engineers validate their change across all dimensions of data quality.
The most effective and quickest approach to improve the quality of data at the deployment stage is to diff the data before and after the change to ensure that the changes applied are indeed correct in terms of data accuracy, data completeness, business logic as well as doesn’t break any downstream data applications.
This capability is unlocked through the open-source data-diff tool:

The most effective way to implement data diff is to integrate it in the pull/merge request review and approval process so that both the author of the change and the reviewer have the full context on how a change will affect the entire data pipeline:
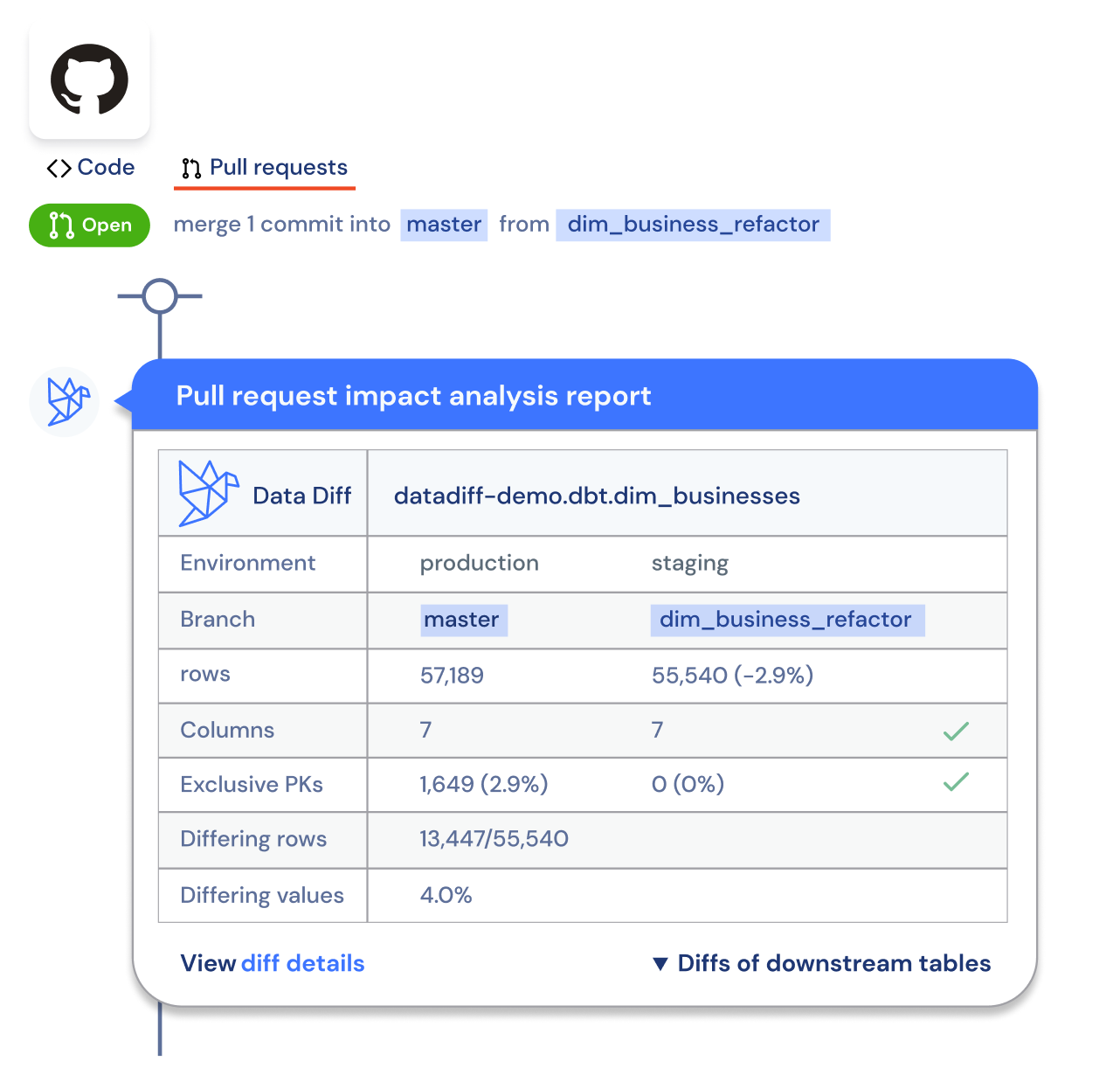
For teams looking for a more powerful, visual diffing experience and turnkey integration with CI, Github/Gitlab, and tools such as dbt, Datafold Cloud provides a seamless solution.
Step 3 (optional): Implement assertions
It is also a good practice to write data assertions using tools like dbt tests (if dbt – data build tool – is used to manage data transformations) or great_expectations. Since writing and curating assertions is a manual and slow process, the best practice is to implement them to validate the most important business assumptions about the data.
Level III – testing during development
In Level II data quality testing, we tested data during the deployment phase, i.e., when a pull request was opened in a code repository, and a change was about to be deployed to production. Can we extend data testing further to the left before the code is even checked in the repository?
Absolutely!
For one, modern IDEs such as VSCode and JetBrains offer intelligent code analysis and can help you avoid issues such as SQL queries that don’t compile or Python scripts that crash upon execution. There are also powerful extensions for specific data technologies, such as dbt-power-user that provides convenient methods for dbt developers.
Second, data diffing can be applied to the development process. Instead of running data diffs in CI for every commit or pull request, we can run them for every iteration of the code to see how the evolution of code logic changes the output data.
Analytics engineers developing dbt models can take advantage of the native integration with dbt that allows diffing models in one click.
Conclusion
If your data team operates data in a mission-critical way, your business cannot afford to rely on bad data in production, or your team is simply exhausted from reacting to alerts and angry stakeholders – shifting data quality management to the left is a must.
Automating data testing in deployment is the quickest way to achieve good data quality while maintaining high development velocity.
Datafold is the fastest way to validate dbt model changes during development, deployment & migrations. Datafold allows data engineers to audit their work in minutes without writing tests or custom queries. Integrated into CI, Datafold enables data teams to deploy with full confidence, ship faster, and leave tedious QA and firefighting behind.