
Is Datafold the right data quality testing tool for you?






If we asked data practitioners how they tested their data ten years ago, it’d be a mixed bag of answers:
- Unit testing
- Hacky Excel comparisons
- Upsert failures
- Spot checking queries
- …Not at all
Today, if you ask an analytics practitioner how they test their data, it’s still a bit of a mixed bag:
- dbt tests
- Spot checking queries
- Hacky Excel comparisons
- Unit testing
- …Not at all

You may have noticed that the way people transform and interact with data has changed considerably (thank you Redshift and dbt 😉). But things haven’t changed all that much as to how people test their data! dbt tests made assertion-based testing accessible. Data observability tools helped catch data anomalies. Testing suites like Spectacles were created to test BI tool assets.
And yet data teams are still dealing with massive or regular data quality issues (or worse, don’t even know they have data quality problems).
This is where Datafold comes in: the data quality testing platform that surfaces data quality issues before they happen. We leverage data diffing—value-level comparisons of two tables in your data warehouse—to perform robust testing on your data, allowing you to find the expected and unexpected changes between your development and production environments.
But is data diffing and Datafold the right solution for you? We don’t claim to be a catch-all for all data quality needs (such as data cataloging), but we recognize that there are specific situations in which data teams using Datafold thrive:
- Your organization has either already adopted or is planning to adopt modern data stack (MDS) technologies. This would include a cloud data warehouse, dbt for transformation, or ETL tools for loading and replicating data.
- Your data transformations are SQL-based, whether they’re in dbt or stored procedures.
- You’re using version control to keep track of transformation changes. Bonus points if you have continuous integration (CI) setup to deploy your changes.
- You have a team of developers, engineers, or analysts regularly contributing to your analytics work.
- When data quality issues happen, they halt your team and business. As a result, your data team is highly optimized for data quality.
If your organization or team doesn’t meet all of these criteria, that’s ok! Every data team is on their own journey to creating highly-trusted data. Data diffing and Datafold usually have a role during every part of these journeys.
How we think about testing
Before we go into greater depth about the assumptions we lay out above, it’s important to share some backstory on how we came to think about data testing. And at Datafold, we’re a little (ok, a lot) opinionated on all things data quality testing:
- High data quality is a byproduct of a great workflow, not luck: And a great workflow involves always testing your data during development and deployment. Developers should not have to write manual SQL checks or “eyeball” the data for correctness. Instead, they should leverage a testing methodology and platform that supports automated and robust testing operations. Automated testing during deployment (your CI process) is also the ultimate way to block potential data quality issues.
- There exists a fundamental gap in data quality testing: dbt assertion-based tests and unit testing are great at catching anticipated issues (null or duplicative primary keys, for example), but struggle to find the unanticipated data issues with code changes. (E.g. there’s no dbt test that can tell you whether the LTV of a user has changed between your production and dev spaces.) This is what data diffing fills—a data testing method that provides a robust view on how your data is changing with your code change. When you diff your data, you see both the expected and (more importantly) the unexpected impacts on the data from your code changes.
- Your data should be changing over time, but you should have complete knowledge and control over how it is: Datafold is not going to tell you if your data diffs/changes are good or bad (because oftentimes you want your data to change). Instead, Datafold will give you the information you need: how is the data potentially changing and which downstream tables or BI assets would be impacted. This enables you and your team to make the most informed decision before allowing a code change to merge into your production pipeline.
- Column-level lineage is the best way to understand your data’s lifecycle: Granular column-level lineage allows data teams to fully understand the flow of data in their systems—both in and out of your dbt project. By leveraging column-level lineage, data teams can know exactly which columns and downstream assets like BI dashboards are potentially impacted by code changes. This is one of the main reasons Datafold Cloud supports Looker, Mode, Tableau, and Hightouch integrations, so you know exactly where your data is used and when it will be impacted.
- The only way to guarantee parity in a feasible timeframe during a data migration or replication validation is to use cross-database diffing: If you’re transitioning to a MDS or replicating data across warehouses, data diffing is the most efficient way to automate table comparisons across databases. Most cross-database comparisons require (a lot) of manual SQL, back-and-forth between systems, and time, but by using an automated diffing tool like Datafold, knowing parity between systems can take minutes, not hours.
Is Datafold a good fit?
Below, we’ll walk through some of the assumptions we make about Datafold users, and why we think these assumptions allow users to take the greatest advantage of all the unique features Datafold has to offer.
Your organization has either adopted a modern data stack or is migrating to one
At Datafold, we think MDS technologies are a great way to create a scalable analytics stack. Whether your team were early adopters of a MDS or you’re migrating to one now, Datafold fits seamlessly into MDS technologies. Because Datafold supports cross-database data diffing for migration/replication validation, and development and deployment testing for dbt, Datafold can be there for every part of your journey to the MDS: from migration to scalable growth.
Your team leverages dbt or other SQL-based data transformations
If you define your data transformations using dbt and SQL, you can version control your code changes and implement CI/CD processes. By using dbt to develop your data transformations, you can quickly diff between the prod and dev versions of models to see exactly how these versions differ upon your code changes. Datafold also integrates with dbt Core and dbt Cloud, allowing you to diff your data during development (while you’re building or editing your dbt models) and deployment (while your PR is being reviewed and prepared to enter production).
You have a team of developers regularly working on updating your data models
The best way to ensure your data work is high quality is through collaboration. If you version control your SQL-based data transformations, you’re going to have other users reviewing PRs, merging your work, and ensuring things look correct. Team members that have transparency into the data and code you’re changing reduces:
- Single points of failure by not having only one person who knows how the code works
- The risk of incorrect code changes slipping through
Sharing diff results directly in your git PR with Datafold Cloud allows you and your team members to:
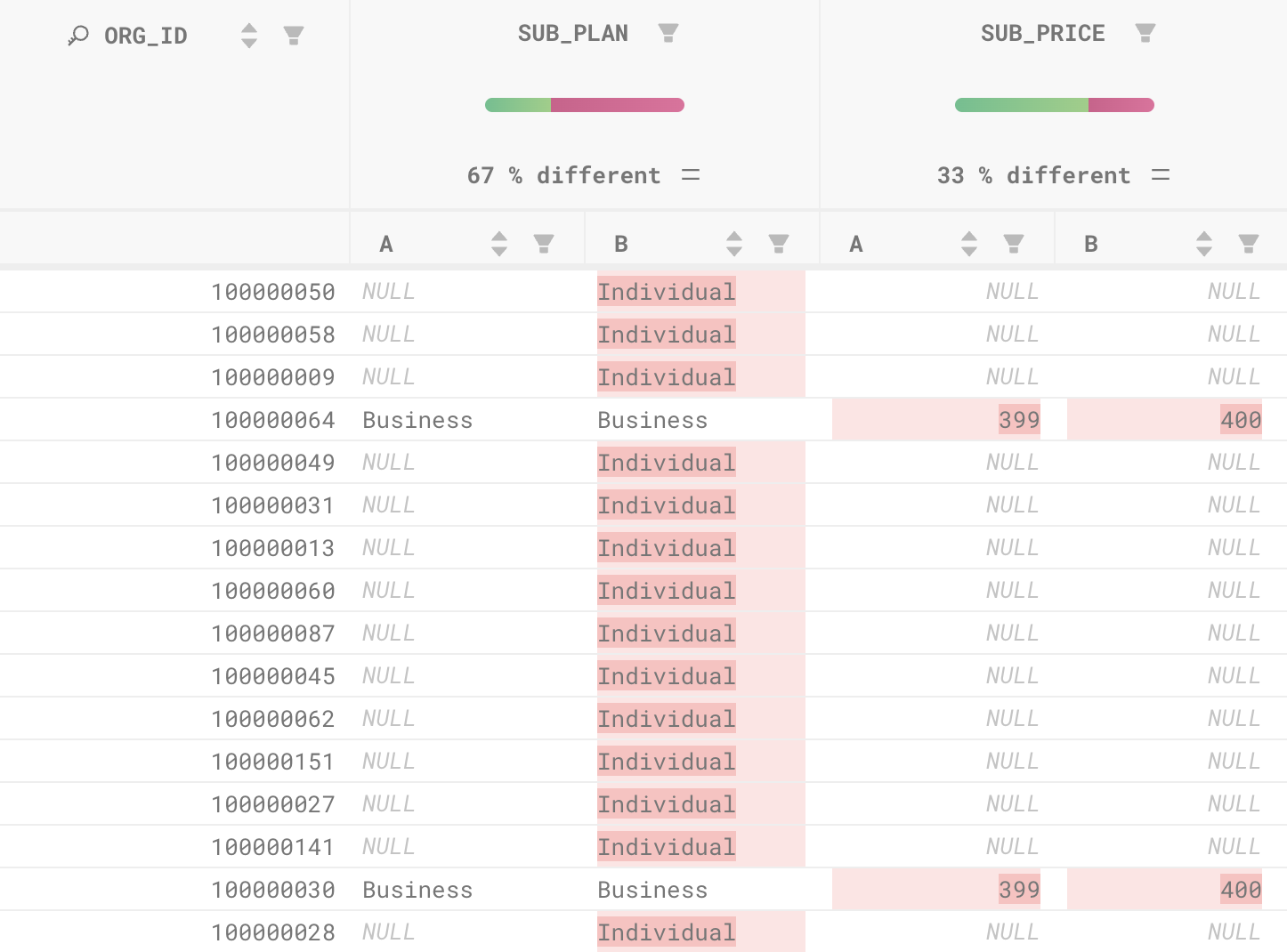
- Clearly see how the prod and dev versions of your tables differ,
- Understand how the individual values may have changed, and
- Identify the downstream dbt models, BI tools, and data apps will be impacted by your code changes.
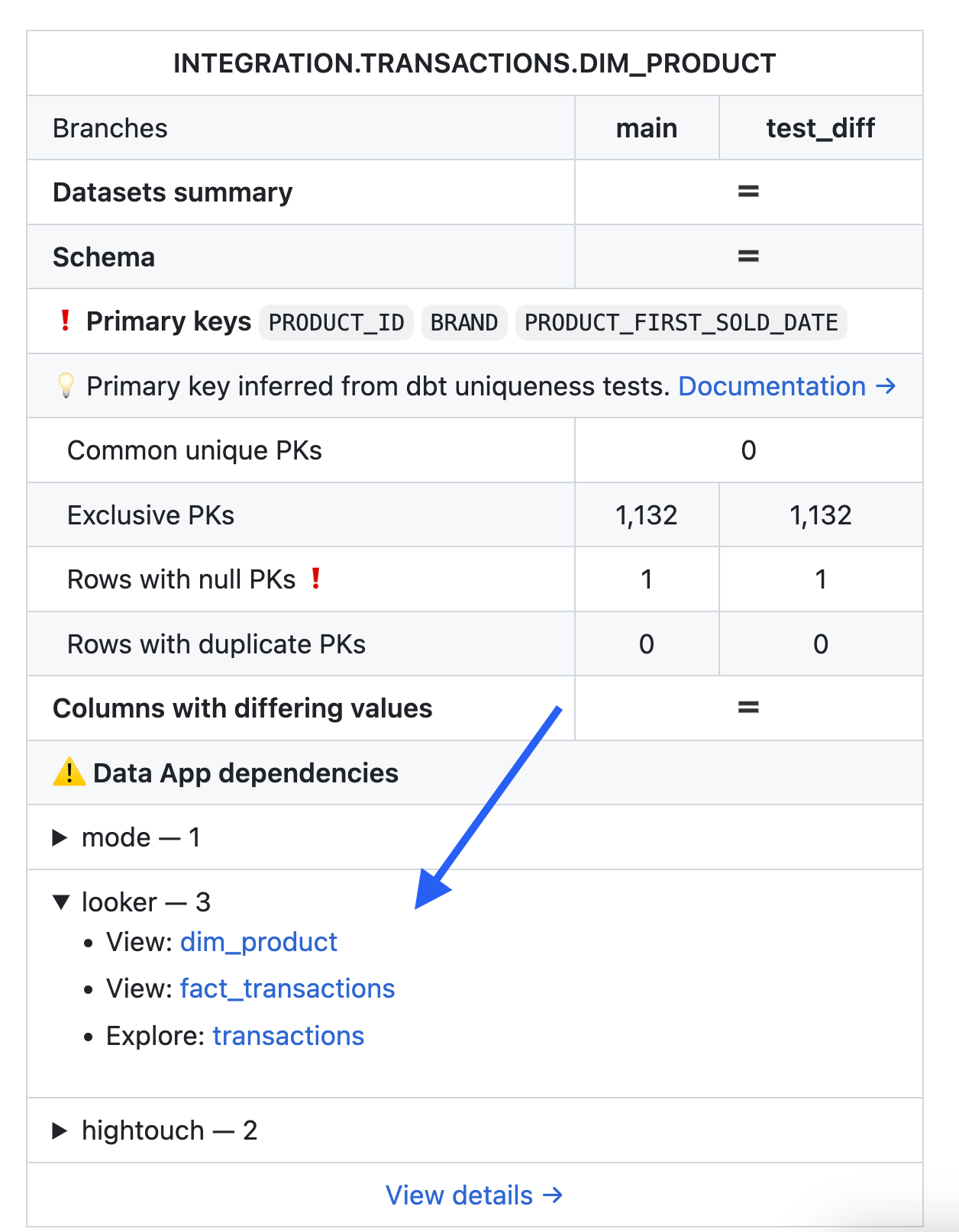

You're committed to finding data quality issues before they enter production
dbt tests and data observability tools are awesome—the more “eyes” on data quality the better! But we also believe that a data quality testing workflow that doesn’t allow you to ship bad (and unexpected) data—like one that Datafold supports—is the first step to preventing data quality issues from happening in the first place.
By knowing exactly how your data will change with a code update using Datafold, from the value-level comparisons or high-level diff overview, your team has the ability to approve or deny these changes with confidence and prevent untested or unapproved data from entering your production environment. If you’re committed to finding data quality issues on the left-side of your workflow, Datafold and data diffing are strong fits for your team.
“Datafold's Data Diff is the missing piece of the puzzle for data quality assurance. When I first heard about Datafold, all I could think was ‘Finally;’ — it’s an unspoken problem that we all know about and no one wants to talk about. Datafold gives us full confidence when we ship changes into production, which historically I couldn’t say about PRs."
- David Wallace, Data Engineer at Dutchie
Your team (and business) are highly optimized for data quality
This is not so much a “tech fit” check as it is a “culture fit” check. We’ve talked to countless data teams where high data quality is not only a nice-to-have for them, but something that can have serious legal and regulatory consequences if incorrect. Every data team wants their business users to have the highest quality data, but we’ve seen that data teams often get an incredible amount of value from Datafold's testing method when they must get the data right.
This is not a hard requirement; if your team is working towards improving your data quality or struggling to wade through dbt test failures, Datafold is a fit for your team. We call out data teams here that deal with strict regulatory and data requirements where high data quality is a non-negotiable, that we’ve seen Datafold’s testing capabilities particularly filling a critically important need.
What our products support
If your team meets any of these criteria and is interested in getting started with data diffing and Datafold, we have two primary points of entry:
- For individual developers, open source data-diff is a great place to start understanding the power of data diffing during development. You can use open source data-diff in the command line interface, or install the free (!) Datafold VS Code Extension for a more seamless user experience.
- For teams that want the power of data diffing during development and deployment, expanded column-level lineage, and access to a secure environment, Datafold Cloud is the place to get started. Also, if you’re getting started on your journey with the modern data stack, Datafold Cloud supports cross-database diffing, so you can validate parity across data warehouses in minutes (not days). To learn more about how Datafold Cloud can enable your team to produce their highest quality work, please reach out to our team!
You may have convinced me…
Amazing! (I am an ex data-person turned marketer, definitely not the world’s greatest salesperson.) Jokes aside, this is personal for me: I have felt the pains of introducing bad data to important BI reports. I know the immense anxiety about a dbt code change because I wasn’t sure who or what it was going to impact. I went through a database migration and spent weeks of my life completing manual comparisons between hundreds of tables in different warehouses.
If you’ve felt these pains before, you’re the reason we built Datafold and brought data diffing to the analytics workflow. If you want to learn more about it, be our guest! Below are some of my personal favorite resources that explain the pain points Datafold wants to remedy:
- ❓ What the heck is data diffing?!
- ⌛ When it’s time to level up your dbt tests: 5 reasons to consider adopting data diffing
- 📺 Join us for a live demo of Datafold Cloud, so you can get all your pressing (and 🌶️) questions answered
- 📲 Reach out directly to our team to learn more about Datafold and how it can help your team work with more confidence and speed
Datafold is the fastest way to validate dbt model changes during development, deployment & migrations. Datafold allows data engineers to audit their work in minutes without writing tests or custom queries. Integrated into CI, Datafold enables data teams to deploy with full confidence, ship faster, and leave tedious QA and firefighting behind.