
Datafold in CI is for everyone (even if you don’t use dbt)






Datafold enables data developers to ensure their SQL code changes don’t break production data.
Until recently, we’ve predominantly shipped Datafold in CI (continuous integration) for teams using dbt. In this post, we’ll show you how data diffing in CI is possible for all data teams—regardless of your data transformation tools.
Taking a step back: What is Datafold in CI?
Thousands of data and analytics engineers use Datafold in CI to see the future impact of their code changes before the code is merged, shipped, and executed in production pipelines.
With Datafold in CI, you will automatically be served a comment like this, containing a future impact analysis, when you push code to a pull request:

You can then click through to view value-level data differences in the Datafold application:
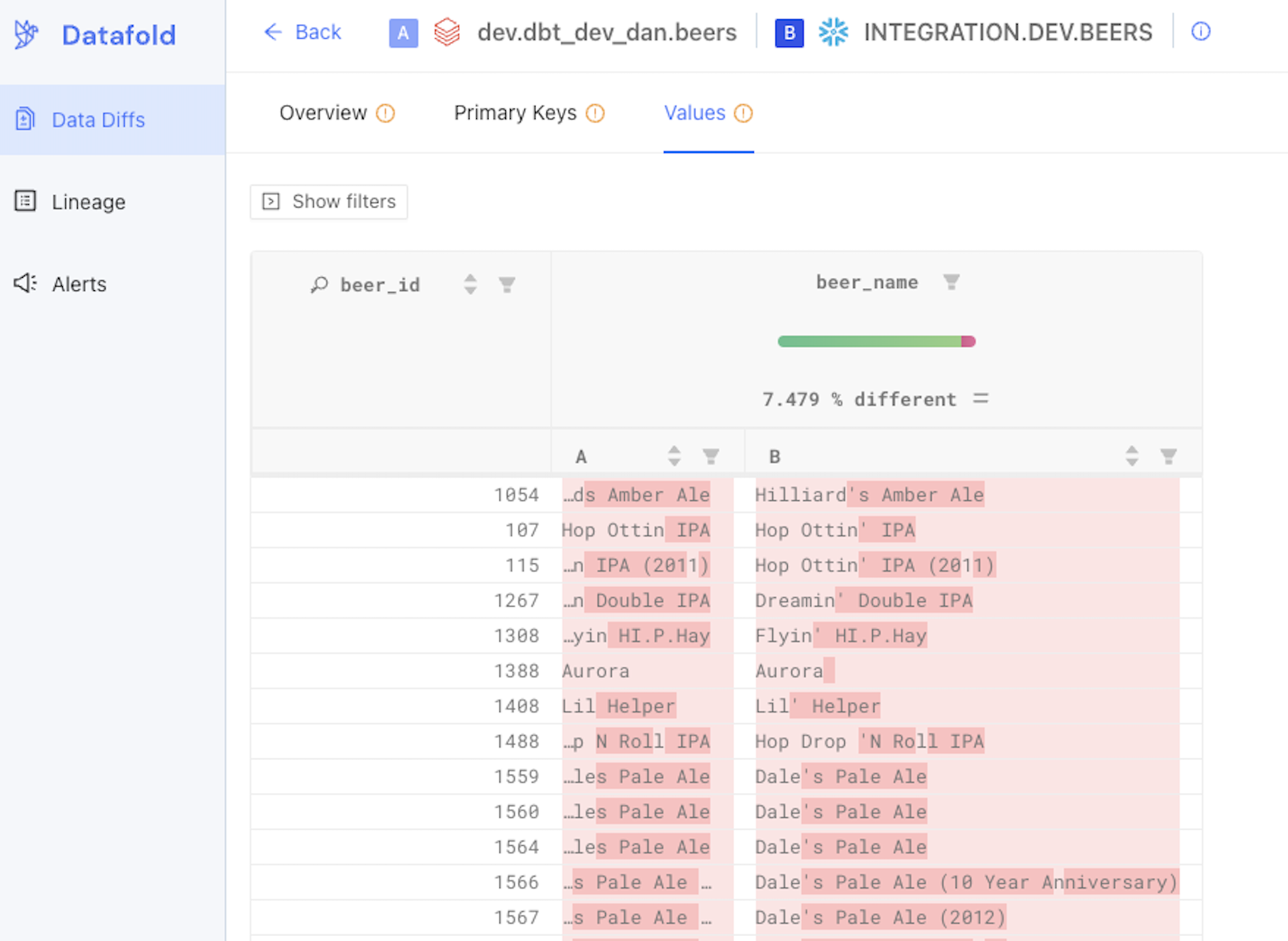
The power of data diffing in CI is that you can catch data changes and errors that assertion tests (which check for accepted values, ranges, and validation) will not catch. 😱
For example, in the above example, both usd and CAD are valid data values (as are 65.00 and 65.10). All your typical tests would pass.
However, the fact that the data is changing based on the code changes could cause a breaking change that would not be evident from a git diff or a standard test suite.
Data developers should have information about breaking data changes in front of them before merging code.
With Datafold in CI, this future impact analysis is automatically presented to the code author and reviewer in their version control tool–with support for GitHub, GitLab, Bitbucket, and Azure DevOps.
Even if you don’t use dbt, CI and data diffing should be accessible to you
ICYMI—open source data-diff and Datafold Cloud closely integrate with both dbt Core and dbt Cloud. The Datafold team (many of us with experience in analytics and data engineering) knows the immense value of using dbt for transformations, as well implementing CI in the dbt deployment process.
However, we also recognize that many data teams do not use dbt—or they use other orchestration tools alongside dbt. We’ve seen data teams using everything from the truly classic (iconic?)—stored procedures, cron, Airflow, and homegrown solutions—to newer solutions like Dagster, Keboola, Prefect, and Shipyard.
Regardless of how you choose to transform, orchestrate, and deploy your data, we want to empower all data developers with Datafold Cloud’s automated data testing in CI. We know what happens when you start data diffing in your CI process—you find unforeseen data quality issues before they happen, establish governance for your data quality testing, and streamline PR review processes.
And those benefits belong to all data practitioners.
Below, we’ll do a technical deep-dive into how to actually implement Datafold Cloud’s CI testing in your deployment process for data teams that use a variety of transformation technologies.

How to set up Datafold Cloud in CI with any orchestration and transformation tool
Anyone can add Datafold Cloud data diffing to their CI pipeline. The key steps to accomplish this are:
- Build staging data
- Tell Datafold what to diff
Below, we’ll walk through how exactly you can accomplish this.
1. Build staging data
In order to run data diffs, your CI scripts need to build a version of the data in a dedicated staging environment. This environment typically exists in a dedicated schema in your database.
The simplest version of building a staging environment is to run the entire code from the pull request branch. This will create an entire version of the data representing what the data would look like if you merged the pull request code and ran your production pipeline. This is a great option if your data is not massive.
Alternatively, you could build only a fixed set of tables that you deem critical to analyze for impact before any pull request is merged.
Finally, with a bit of code analysis and manipulation, you can update CI to build a staging environment containing only the tables that are modified in the pull request, and potentially the downstreams as well.
Regardless of which tables you build in your staging environment, the existence of a staging environment enables Datafold to compare the staging version of a table to the production version of the same table, and write data diff results to the pull request.
What it might look like to identify modified tables
If you opt to diff only modified tables, you’ll need to write some code to identify these. This is possible using a tool like GitHub Actions, Circle CI, or GitLab CI. These tools allow you to run bash commands and execute Python scripts.
Let’s say your pull request modifies the code that generates MY_DB.ANALYTICS.DIM_ORGS, your CI pipeline could use git diff (or similar) in a CI step to compare the two git branches and identify that this table was modified in the pull request branch. Then, your pipeline should build a version of that table using the code in the pull request branch, named MY_DB.PR_NUM_123.DIM_ORGS.
Such a git diff command might look like this:
This command assumes one SQL file per table, with the file name equal to the table name. Your naming structure will likely be different and require a unique programmatic approach to identifying table updates. If your SQL code repository doesn’t have a consistent structure that is conducive to such an approach, you may choose to always diff a defined set of files.
No matter the structure of your SQL code repository, or your experience level with this type of scripting, we are happy to advise!
2. Tell Datafold Cloud what to diff
Once you’ve built staging data and determined which tables should be diffed, you’ll need to submit information about what should be diffed to Datafold using our SDK.
You might have noticed that in the git diff command above, the result was written to a file, git-diff.txt. This file now exists within your CI environment or container. git-diff.txt will now be used for two purposes, both related to telling Datafold Cloud what to diff:
Identify downstreams
To identify the tables that are downstream of the modified tables, Datafold Column-Level Lineage can be accessed via Datafold’s SDK from within your CI script. Ideally, every table identified in git-diff.txt should also be diffed.
By analyzing your pull request code and querying the Datafold Column-Level Lineage, you can identify all the tables that need to be diffed.
Submit the modified files and downstreams to Datafold
Finally, combine a list of the tables identified using git diff and (optionally) the downstreams into one file. Let’s call it tables_to_diff.txt. The structure of tables_to_diff.txt should look something like this:
Finally, this information can be sent to Datafold Cloud!
Datafold will then automatically write data diff results back to the pull request.
.png)
Let’s be honest–setting up your CI pipelines to meet your specific data environment and infrastructure can be intimidating. If you’re thinking, “Hmm, I’m not sure if this will work for me,” please do not fear! Allow me to reassure you with three points:
- You’re not alone–it does take up-front effort to set up amazing CI. But the long-term benefits—consistent testing standards for each PR, data quality governance, and greater visibility into code changes—are worth the up-front investment.
- Don’t let the perfect be the enemy of the good. For example, even if you don’t identify downstreams, it can still be extremely valuable to diff a core set of hard-coded tables.
- It is our job at Datafold to make this easy for you–we are here to help.
By adding Datafold Cloud to your CI pipeline, you can superpower data developers and code reviewers with detailed information about the future impact of the proposed code changes.
Datafold is the fastest way to validate dbt model changes during development, deployment & migrations. Datafold allows data engineers to audit their work in minutes without writing tests or custom queries. Integrated into CI, Datafold enables data teams to deploy with full confidence, ship faster, and leave tedious QA and firefighting behind.