
Data migration challenges and how to overcome them






Five words that will send shivers down any data practitioner’s spine: “we’re undergoing a data migration.”

But why do data migrations strike such stress into the hearts of data teams, and what are methods to reduce that stress?
Data migrations are often complex, time-consuming, and expensive projects for organizations to undergo. You risk:
- Data loss or change
- Never receiving stakeholder sign-off
- Not completing or investing in other important data work during a migration
But you also gain (in the longer term), systems and tooling that scale with your business, cost efficient solutions, and governable platforms and workflows.
In this blog post, we’re going to unpack some of the common challenges during a data migration and demonstrate how modern tooling and Datafold are reducing the risk and speeding up the time it takes to complete one.
What is a data migration?
A data migration is the process of migrating an existing data source, data warehouse, or transformation tool—or a combination of these things—to new tooling and systems. For many data teams, migrations look like the adoption of modern data stack tooling: ETL tools, cloud data warehouses, and modern transformation tools.
But not all migrations look the same. Common data migrations include:
- Complete overhaul: During this months to years long migration, data teams undergo a complete overhaul of their data stack to embrace modern technologies. During a migration like this, data teams will typically adopt new ETL tools like Fivetran and Airbyte, new cloud data warehouses like Snowflake and BigQuery, new data transformation workflows like dbt, and maybe even newer BI tools. These migrations are often very complex and time-consuming, but necessary for long term scalability and cost efficiency of a data organization.
- New data warehouse: Oftentimes data teams will need to migrate only their data warehouse, opting for modern and efficient cloud data warehouses like Snowflake, Redshift, Databricks, and BigQuery. In a migration like this, data teams are concerned with ensuring parity of tables between their legacy and new data warehouse—what we call the “lift-and-shift” method. Once all the data is moved, teams will focus on longer term refactoring and optimization of tables.
- New data transformation workflow/tool: Many data teams are moving their data pipelines to more modern and flexible transformation tools like dbt. During workflow migrations like these, data teams are primarily concerned that their new transformations produce the same output as their legacy ones.
- New source data: If you’re moving an existing data source to a newer one—say you’re migrating from HubSpot to Salesforce or Segment to Rudderstack—you’ll want to ensure the data from your new system matches your old data source. This is less of what you think of for a typical migration, but can happen as your organization outgrows tooling.
Benefits of a data migration
Why are data teams spending hours, months, and potentially years to migrate to modern tooling? Many of the reasons have to do with scalability, costs, or governance.
Scalability
Many data teams that are looking to migrate are hoping to scale their data storage and pipelines in more efficient and cost effective ways. Cloud data warehouses made storage cheap and scalable; dbt enabled version controlled data transformations; ETL tools like Fivetran made data ingestion a point-and-click process.
These new modern tools not only relieve organizational strain on legacy tooling, but are built in ways for teams to grow and manage their data and data pipelines at scale.
Also, there's an important human scalability factor to consider when data teams adopt modern tooling. In general, many legacy data warehouses, on-premise solutions, and GUI-based transformation tools have high barriers to entry, leaving many non-technical data team members and business users out of the loop. With accessible data warehouses, such as Snowflake where permissions can be highly customized, and dbt, where transformations are accessible to anyone who knows SQL, the barrier to contributing to analytic works is lowered. This ultimately opens the door for data teams to better serve self-service analytics efforts and create more decentralized, highly-scalable mesh-like data systems.
Cost savings
Switching to a completely new platform or set of tooling usually comes at a cost incentive. For example, if you’re migrating from an on-premise data warehouse to a cloud warehouse, you may have the option to shed considerable costs around on-premise management. Other modern data tools, such as dbt and Airbyte, offer open source solutions that can be managed by your own team.
Importantly, a migration usually means adopting simpler, more accessible tooling. For example, if your team chooses to stop writing your own ETL extraction scripts for a service like Fivetran, anyone can create an extraction and loading process. This reduces overhead costs around complex technical solutions and increases the accessibility of data workflows.
Improved and manageable governance
Modern data tooling offers clear means of governing data. For example, dbt in pair with a cloud data warehouse like Snowflake allows data teams to create restricted roles and user groups to appropriately limit data access. Using a data transformation workflow that uses version control also allows you to leverage CI (continuous integration), where you can establish consistent testing and formatting standards for every code change.
Many of these tools and workflows also offer detailed and accessible ways to monitor cost and usage, so governing expenses can be more visible and programmatically accessible.
Data migration challenges
Let’s be very transparent: there are almost a countless number of ways a data migration can go wrong. And by “wrong” we typically mean a migration has gone over the expected timeline, budget, or resources required to complete one. The list we offer below is not exhaustive, but are some of the problems we see (and have experienced) during data migrations. We see data teams struggle with:
- Validating parity between their legacy and new systems
- Receiving stakeholder sign-off
- Reducing efforts in other analytics work while undergoing a migration
Validating parity between legacy and new data
During a migration, you want to guarantee to your stakeholders that the data between your legacy system and new systems is unchanged. And whether you’re copying data from one data warehouse to another, or changing the tool for your transformation workflows, you risk data loss and (unexpected) change.
But imagine having to validate the parity of hundreds, thousands, or millions of tables. How do you identify which tables you must migrate? How are you actually comparing tables, especially if they’re across different data warehouses? How do you do this in a timeline that meets the needs of your organization?
Datafold Cloud computes data diffs for tables in your different warehouses in minutes, not days. Leverage the Datafold Cloud REST API to reduce the amount of manual queries during a data migration, and instead automate comparisons between your legacy and new data warehouse to validate in parity in an accelerated way.
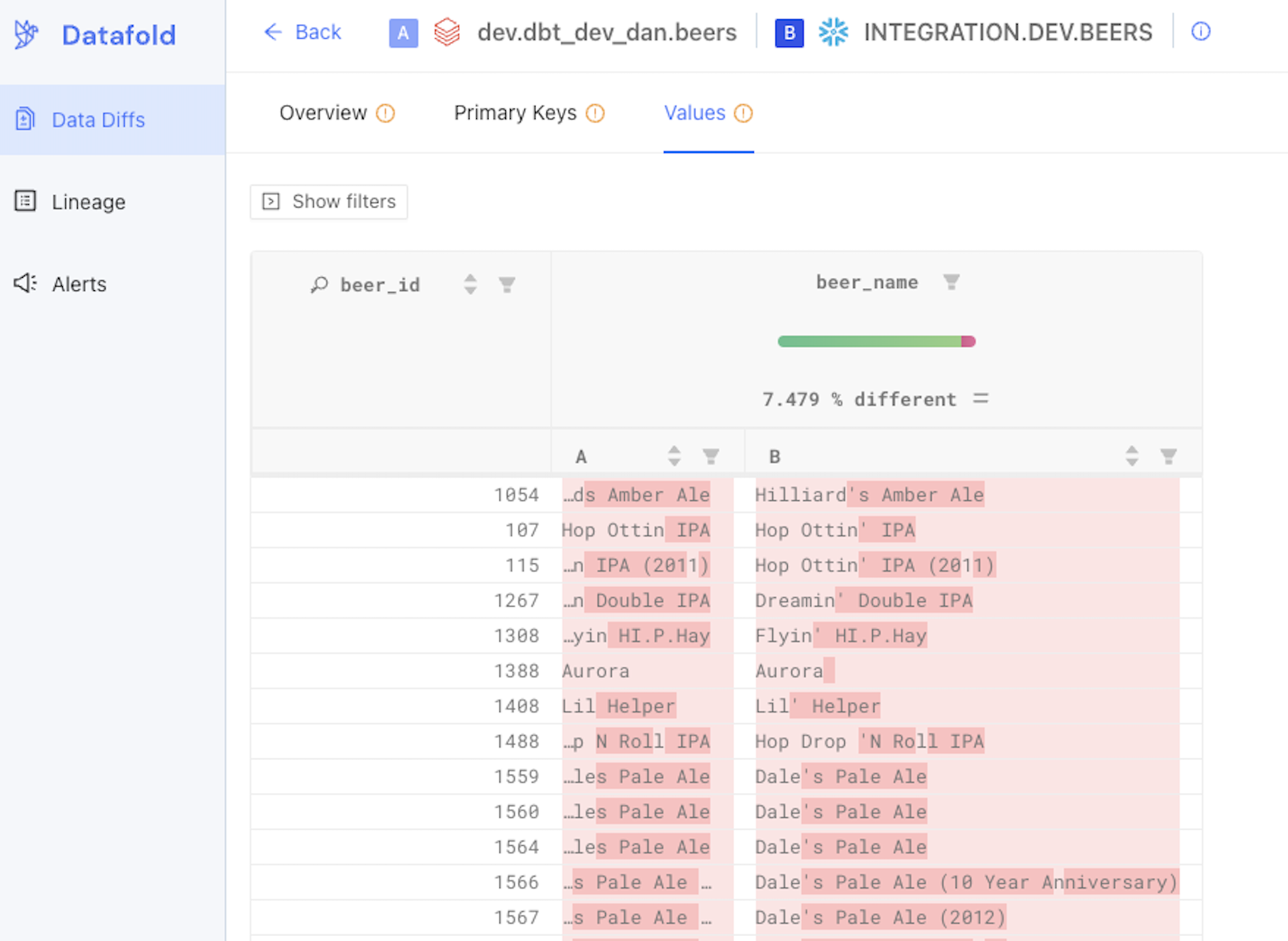
Stakeholder sign-off
A data migration is only complete once your final stakeholder gives you that “LGTM 👍.” But getting that approval—when all they want to know is that their data remains the same—can be incredibly challenging if you can’t prove the data is unchanged between your legacy and new systems. And if it is changed, showing stakeholders these changes are expected and acceptable can be impossible to do if you don’t even know why the data changed.
Doing a migration means you’re spending less time doing meaningful new analytics work
When your team is dedicating weeks, months, or even years to migrating to new systems, you’re, by default, reducing the amount of time and team members that can be dedicated to newer data projects. This can be a considerable challenge when there’s pressing or ongoing analytics work that needs to happen.
Many teams opt to leverage consultants or professional services to help reduce the amount of manual work their teams need to conduct during a migration, relieving them to focus on other important data work.
Datafold Cloud for automated and faster data migrations
Datafold is revolutionizing the way data teams undergo migrations. We leverage the concepts of data diffing, automation, and column-level lineage to ensure your migration happens in a timely and trustworthy manner.
Data diffing
Datafold’s core technology is data diff: row-by-row comparisons of two tables to let you know what has been changed, deleted, or added between the two. As we like to say, “think of data diff as git diff, but for your data.”
Diffing your data during a migration allows you to validate the parity between hundreds or thousands of tables within seconds—whether these tables are in the same data warehouse or in different ones. By using data diff during a migration, you know immediately if data you’ve copied, switched up the transformation workflow for, or received from a new source is different from the original data. Your team has the agency to quickly determine if these changes are expected and acceptable, or if something has gone wrong during the migration.
Data diff results through the Datafold UI also enable quicker stakeholder sign-off. When you can show a stakeholder that your legacy and new tables don’t differ at all, you gain their confidence and approval in a faster and transparent way.

"No question. I would recommend Datafold for any large-scale migration” -Jon Medwig, Staff Data Engineer at Faire.
Read more about how Datafold helped accelerate Faire’s migration by 6 months and encounter zero data quality issues in the process.

Automation at your fingers
Using Datafold Cloud’s REST API and scheduler, you can run data diffs during your migration in programmatic and automated ways. This allows you to validate the parity of tables with automation by your side, rather than relying on thousands of complex manual cross-database queries (and outer joins 😢).
Column-level lineage
For large-scale migrations, understanding how to prioritize the migration of certain tables can be daunting, especially if your team has thousands upon thousands of tables. Datafold Cloud’s column-level lineage enables teams to identify the tables that have many important downstream tables, so your team knows which data to be extra careful with during the migration.
In addition, by leveraging column-level lineage during a migration, your team can prioritize the order of assets to be migrated. For example, if you see that a fct_transactions table is upstream to hundreds of BI dashboards versus a fct_transaction_legacy table that's only powering a handful of dashboards, you're going to want to migrate fct_transactions first. Because Datafold Cloud's column-level lineage is also built by analyzing your warehouse's query logs, you can more easily identify those important ad hoc/random/wild tables built by analysts that somehow power half of the reporting for your organization 🤫.

Conclusion
As we’ve outlined, data migrations are complex and daunting projects—but they’re incredibly important for the long-term scalability of your data stack.
Investing in tooling such as Datafold that can make the more painful and complex parts of the migration—ensuring your legacy and new systems match as expected—fast and less complex. Gartner reports that 83% of data migrations fail; and at Datafold, we don’t want you to join this statistic. Learn more about how your team can move with greater speed and confidence during a data migration today.
Datafold is the fastest way to validate dbt model changes during development, deployment & migrations. Datafold allows data engineers to audit their work in minutes without writing tests or custom queries. Integrated into CI, Datafold enables data teams to deploy with full confidence, ship faster, and leave tedious QA and firefighting behind.