DATA DIFFING
Quickly check for differences between any two tables
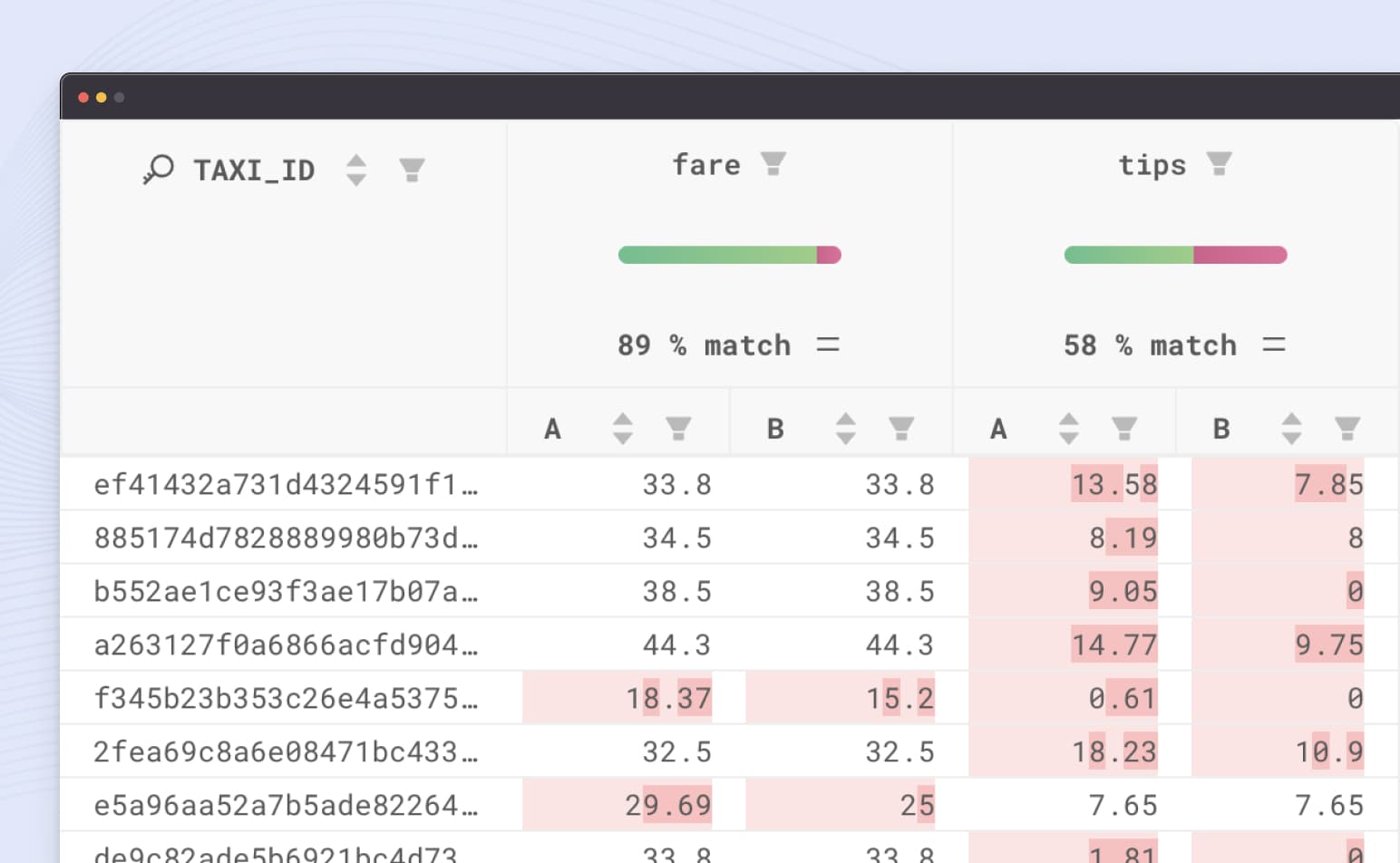
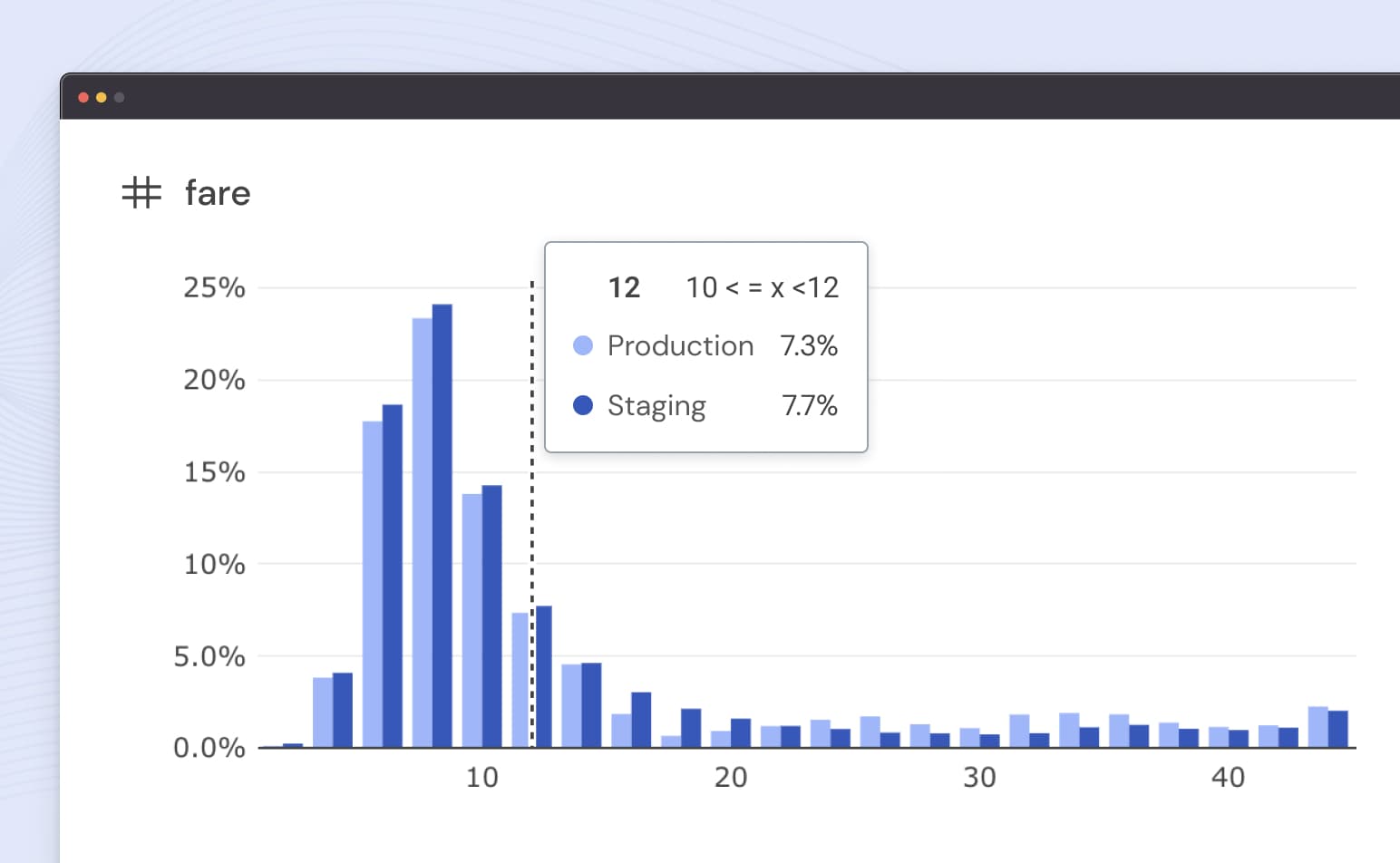
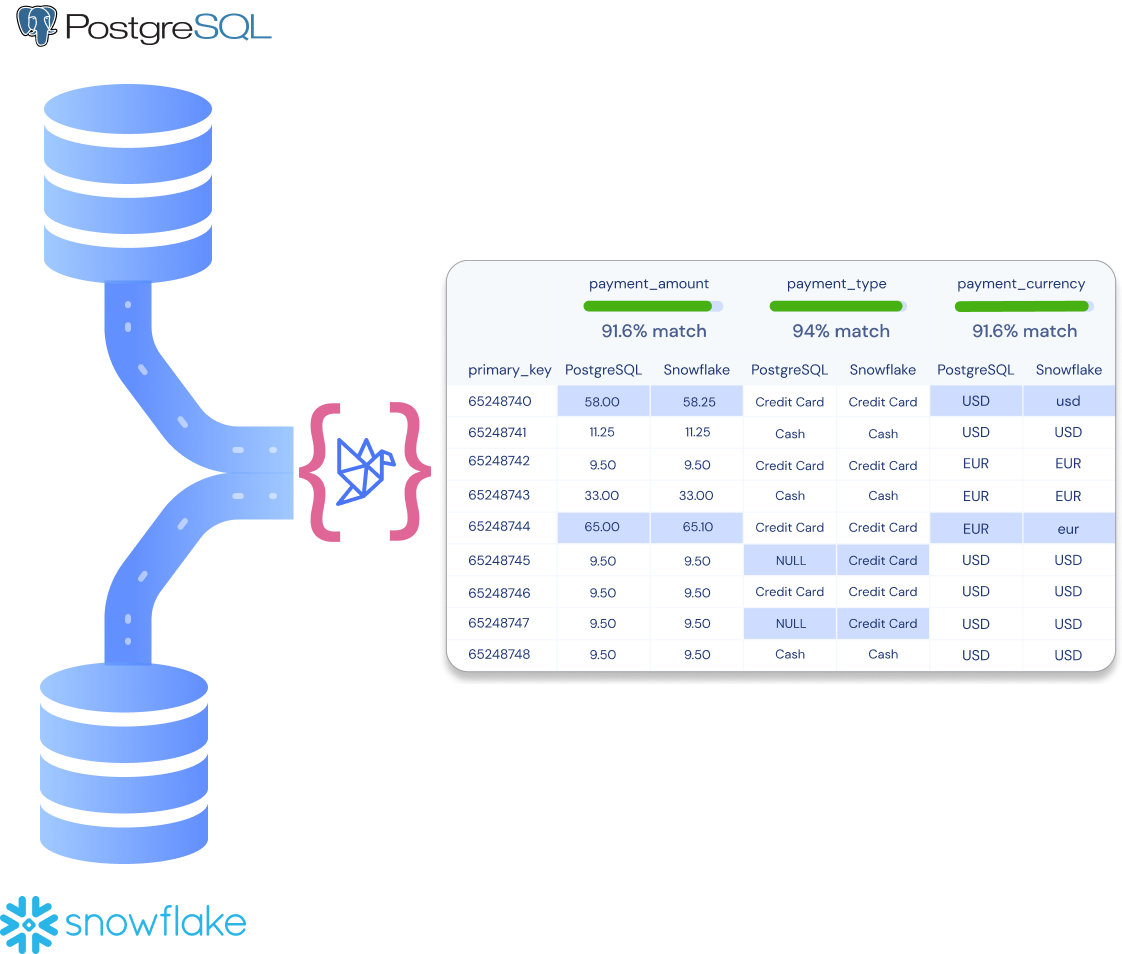
Whether you’re updating a simple dbt model, or undergoing a large migration, know exactly how your data differs between two environments.
At every stage of your data workflow — from migration to deployment — uncover data quality issues before they happen through data diffing, column-level lineage, and CI testing.

14-day free trial—no credit card required!
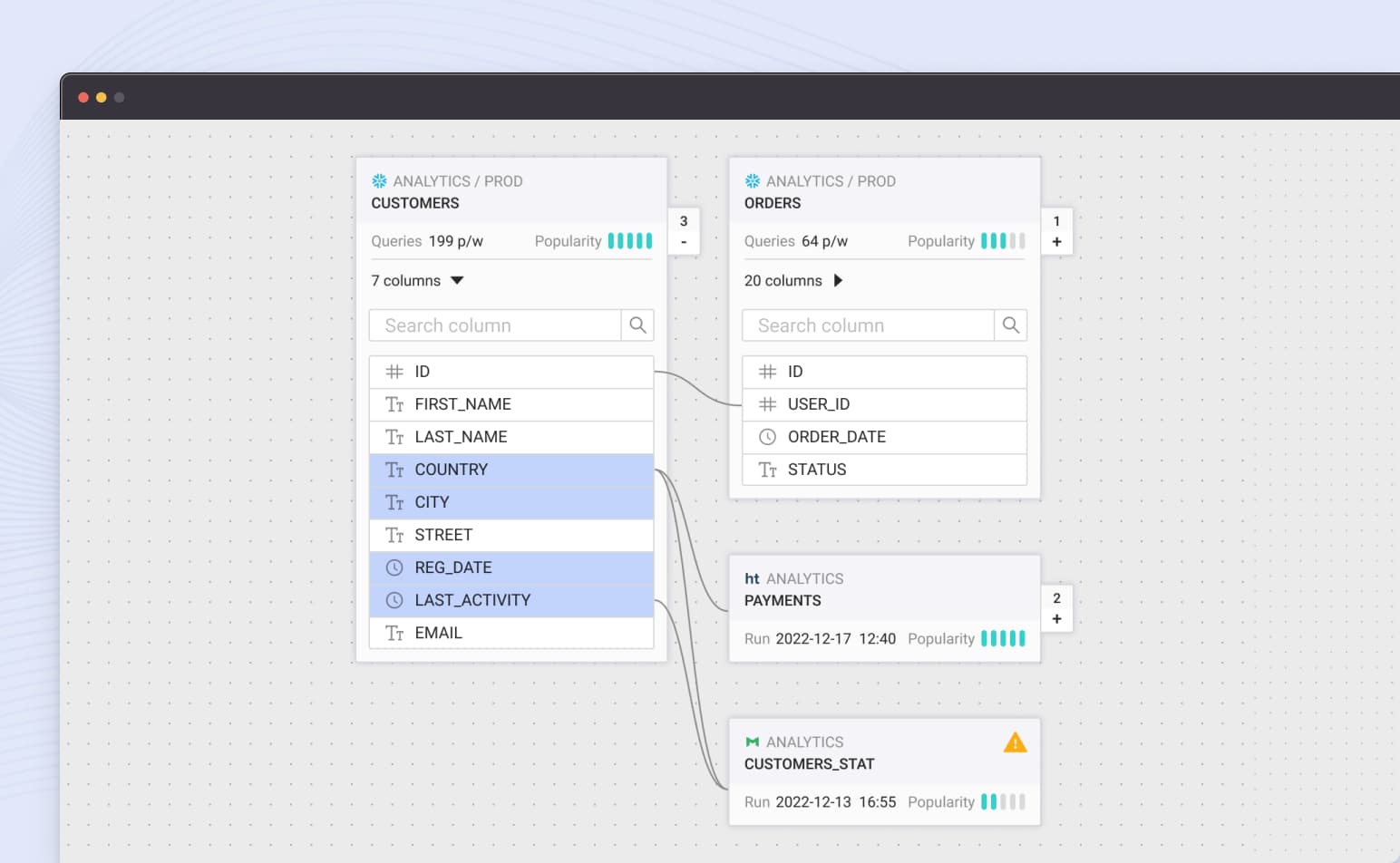
20+ orchestrator, database, & BI tool integrations
Loved by data teams who don’t compromise on data quality













Whether you’re updating a simple dbt model, or undergoing a large migration, know exactly how your data differs between two environments.

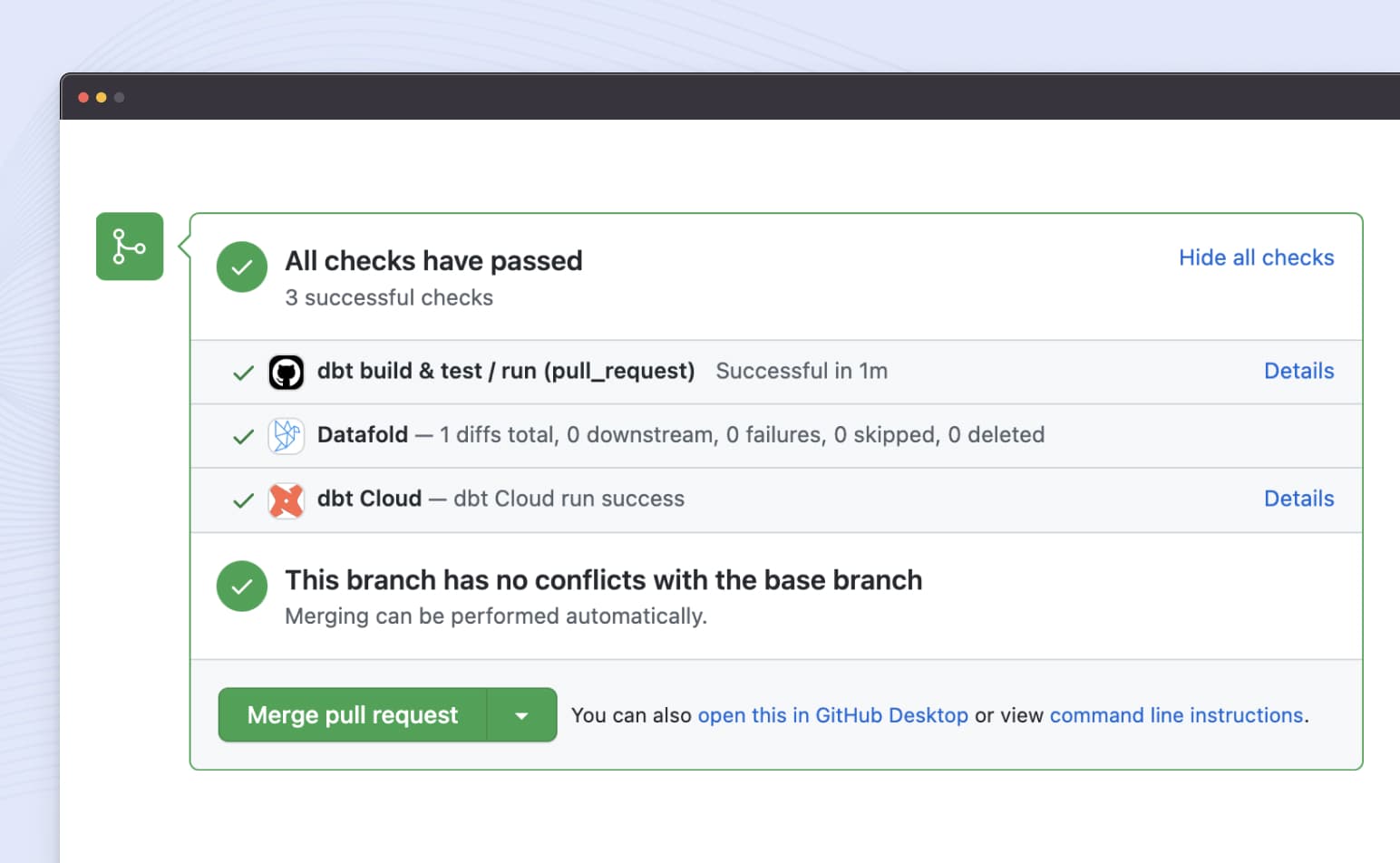
Datafold adds a comment in the pull request stating exactly how your code change will impact production data if merged.
Easily share impact analysis, data diff reports, and column-level lineage with stakeholders before deploying transformation code changes to production.

Built to integrate with your current (and future) data stacks


















Datafold Cloud supports SaaS and dedicated cloud deployment options
Datafold scales to millions of tables, billions of columns and trillions of records
Datafold Cloud is HIPAA, GPDR, and SOC 2 Type II compliant
Get dedicated support from our team of expert data engineers
When you run your data quality tests in Datafold Cloud’s secure and compliant environment, your team can focus on what really matters: providing high quality analytics to your organization and customers.
Eventbrite’s data team sped up PR reviews by 3x and reduced their data quality regressions by 90%

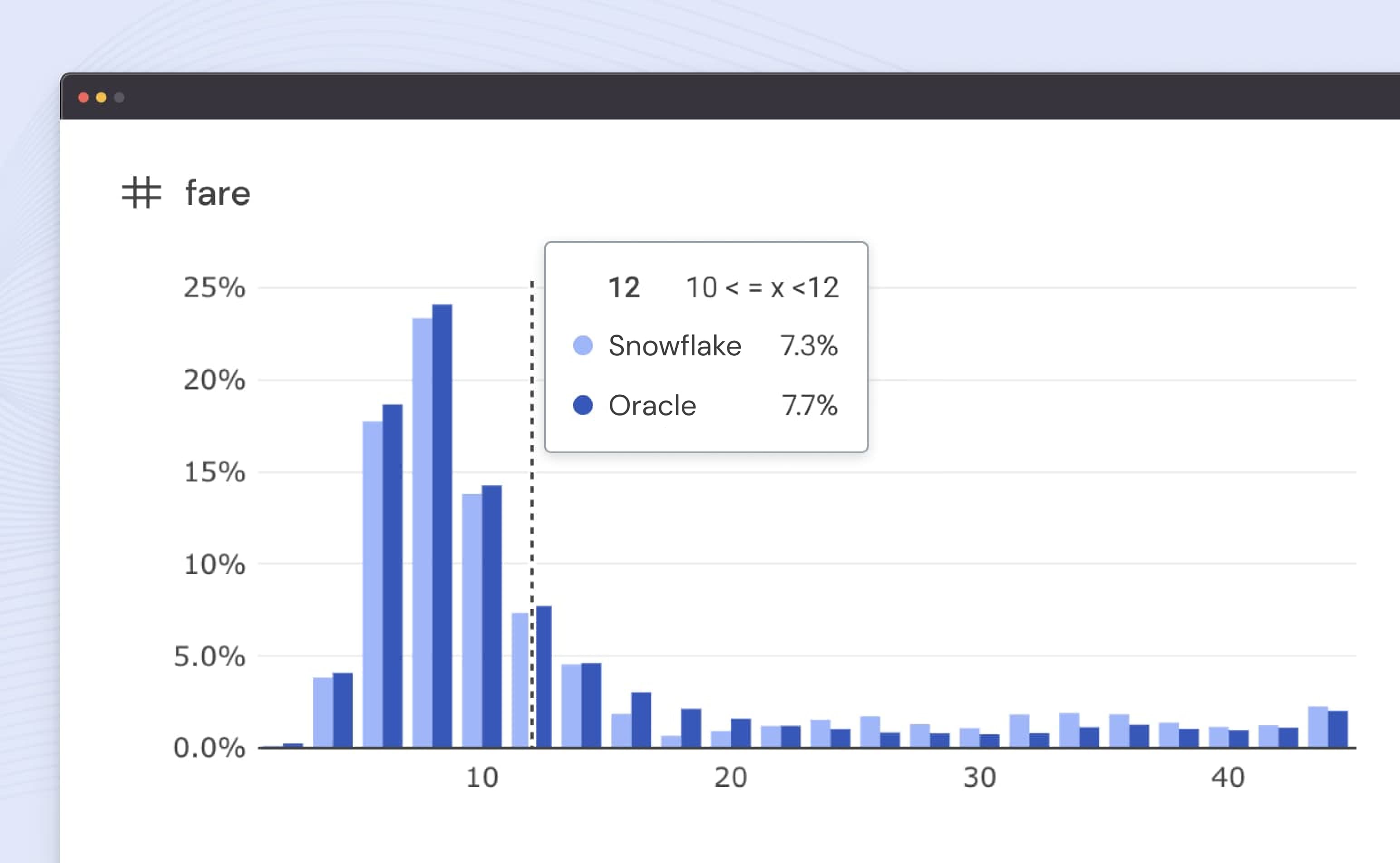
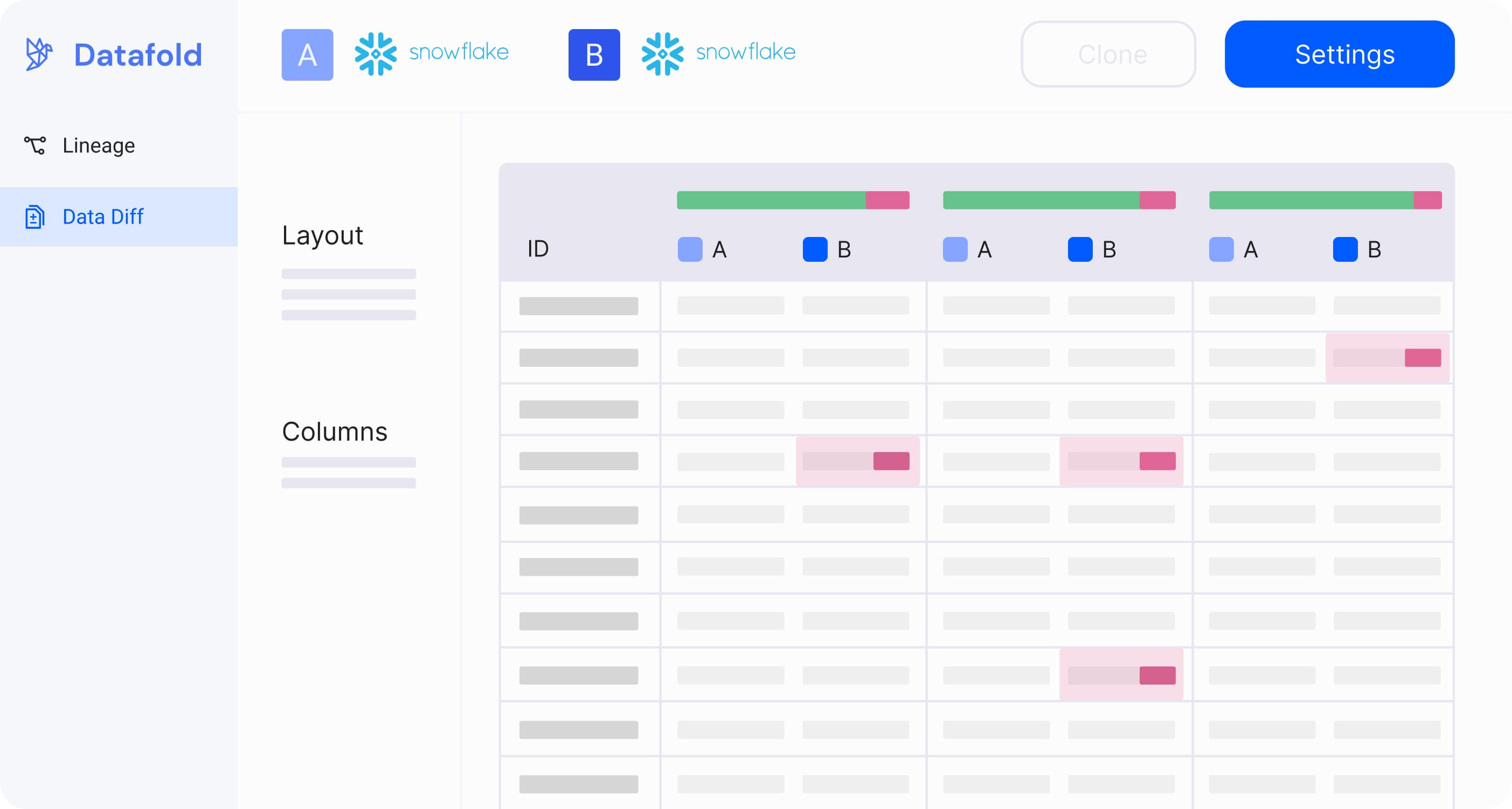
Quickly identify parity between legacy and new transformations or databases using data diff

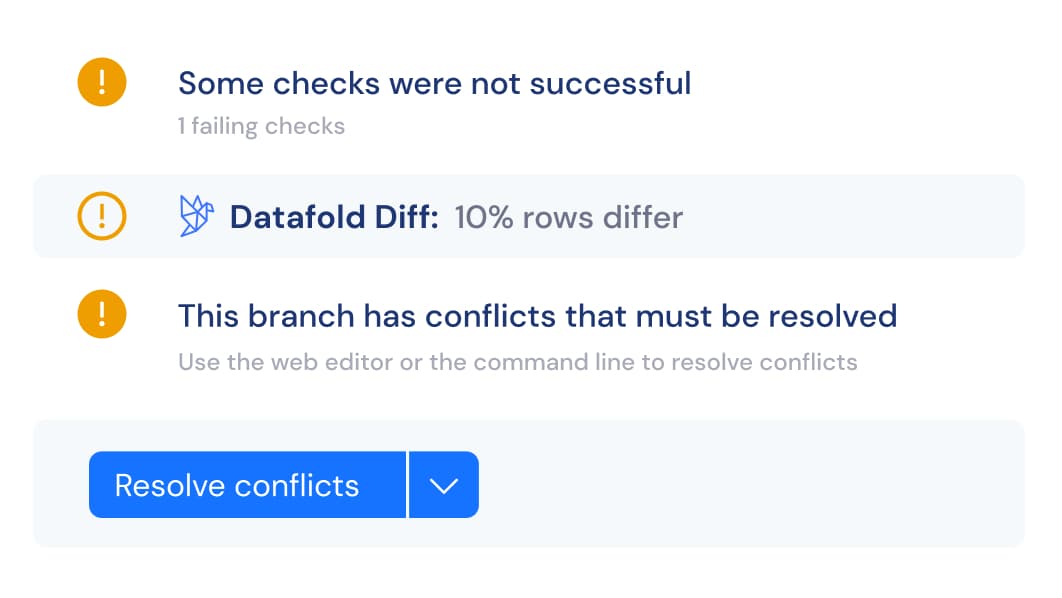
Ensure your mission-critical data is as it should be with Datafold's data diffing and alerting
Add automation and governance to your data quality testing by ensuring every PR goes through the same testing process
saved during the validation process for each new model
rebuilt and validated in Snowflake
"Datafold allows real visibility into data changes before the changes are live, reducing mistakes and enabling our analysts and stakeholders to feel confident in their changes."

data accuracy & quality KPI achievement
faster testing and code review
“Datafold helps you find the hidden changes you didn't know you made to your data, helping you if they’re unintended or understanding what's causing them.”

hours saved per month
increase in productivity
"You can see right off the bat whether your data quality is what you were expecting, and reviewers can see it, too. Now we’re at the rate where we’re automating code reviews, or close to it, on 100 pull requests per month. And this is just the start.”

pull requests checked by Datafold
total operations by Hightouch
"With Datafold, we're not just adding trust to our Snowflake instance, we're adding trust to our most important data that is getting activated via Hightouch."

Don’t wait for stakeholders, monitoring tools, and customers to tell you about broken data.
Adopt a workflow that makes data quality issues a thing of the past.

Supercharge your
workflows
with seamless dbt Cloud and Core integrations
Know exactly what will happen to data and data applications once the code is deployed, right in the pull request. Identify breaking changes, sudden metric shifts and edge cases before they do any damage to the business.
data accuracy & quality KPI achievement
faster testing and code review
of code changes tested before merging to production
“Datafold helps you find the hidden changes you didn't know you made to your data, helping you if they’re unintended or understanding what's causing them.”
Stop guessing what this regex does or arguing if that CASE WHEN statement has correct logic. No more custom scripts and audit spreadsheets to fill.
hours saved per month
increase in productivity
pull requests automatically tested per month
"You can see right off the bat whether your data quality is what you were expecting, and reviewers can see it, too. Now we’re at the rate where we’re automating code reviews, or close to it, on 100 pull requests per month. And this is just the start.”
Stop surprising your data users with unexpected metric changes and broken dashboards. Easily share impact reports with everyone and give heads up before deploying the changes to production.
pull requests checked by Datafold
total operations by Hightouch
Data Quality issues in Production
"With Datafold, we're not just adding trust to our Snowflake instance, we're adding trust to our most important data that is getting activated via Hightouch."
Manual data testing is hard, tedious, and error-prone. Focus on what matters and not on writing boilerplate tests, custom scripts and filling out audit spreadsheets.
payment-related data incidents
reduction in QA time, at a higher level of accuracy
data confidence
“Datafold gives you the ability to QA things in a way that you could almost never do on your own. It’s like a booster shot...you get extra protection and security when you make changes.”



With full visibility into every change, everyone, not just data team, can contribute, because testing and reviewing code is so easy!
hours saved during the validation process for each new model
models rebuilt and validated in Snowflake
data team hours will have been saved once the migration is complete
"Datafold allows real visibility into data changes before the changes are live, reducing mistakes and enabling our analysts and stakeholders to feel confident in their changes."























Datafold scales to millions of tables, billions of columns and trillions of records
Meeting the highest standards for data security and privacy protection
Deploy Datafold automatically and securely in your AWS or GCP account
Get dedicated support from our team of expert data engineers
Choose the type of demo